Supercharge Message Summarization Experience: Parameter-Efficient Fine-Tuning and LLM Assisted Evaluation

Introduction
In today’s business landscape, we are surrounded by a wealth of opportunities to utilize advanced technology powered by AI. Think of large language models(LLMs) as versatile tools in our toolkit: we can customize them for a variety of specific downstream tasks, a process known as fine-tuning. However, a challenge arises in that each fine-tuned model typically maintains the same parameter size as the original. Therefore, managing multiple fine-tuned models requires careful consideration of factors such as accuracy performance, memory management, inference latency, and disk utilization.
Parameter-Efficient Fine-Tuning (PEFT) methods provide an efficient and streamlined approach for adapting pre-trained LLMs, commonly referred to as base models, to a range of specific downstream tasks. These tasks encompass diverse applications, including but not limited to text summarization, question answering, image generation, and text-to-speech synthesis. In contrast to traditional full fine-tuning, which consumes substantial computational resources, PEFT prioritizes the optimization of a significantly smaller parameter subset referred to as “adapters”. These adapters work in tandem with the base model, achieving competitive performance while imposing lower computational and storage demands.
I’ve shared a Colab notebook demonstrating a resource-efficient PEFT process using QLoRA and HuggingFace PEFT libraries to fine tune Falcon-7B-sharded model on SamSum dataset for summarizing “message-like” conversations. It achieves reasonable summarization performance after training for only 5 epochs on an A100 compute instance with a single GPU. Additionally, I’ve employed GPT-3.5-turbo to assess generated summaries, showcasing a potentially automated evaluation method by formalizing evaluation guidelines into a prompt template. This approach stands in contrast to traditional automated evaluation metrics like ROUGE or BERTScore, which rely on reference summaries.
Furthermore, I will also share some insights and lessons I’ve gained throughout this process, with a particular focus on considerations when leveraging LLMs to develop product experiences related to summarization.
I hope you’ll discover this article both informative and intriguing, igniting your creativity as you explore the development of your unique product experiences and strategies through the use of fine-tuned foundation models.
Enjoy the read, and let your innovation flourish. Happy new year!
Fine-Tuning with Model Quantization and LoRA
Base models such as Claude, T5, Falcon, and Llama2 excel at predicting tokens in sequences, but they struggle with generating responses that align with instructions. Fine-tuning techniques, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), can be employed to bridge these gaps. In this sample project, we’ll explore the application of SFT to Falcon-7B, a 7-billion-parameter causal decoder model trained by TII on 1,500-billion tokens from RefinedWeb with curated corpora, for conversation summarization tasks.
Install and Import the Required Libraries
To get started, one can create a virtual environment and install all the required libraries needed for this sample project. In Colab, this can be done by running a cell containing the following scripts:
!pip install huggingface_hub==0.19.4
!pip install -q -U trl accelerate git+https://github.com/huggingface/peft.git
!pip install transformers==4.36.0
!pip install datasets==2.15.0 Tokenizers==0.15.0
!pip install -q bitsandbytes wandb
!pip install py7zr
then the installed libraries can be imported and be used during runtime via:
import torch
import numpy as np
from huggingface_hub import notebook_login
from datasets import load_dataset, concatenate_datasets
from transformers import AutoModelForCausalLM, AutoTokenizer,BitsAndBytesConfig, AutoTokenizer, GenerationConfig
from peft import LoraConfig, get_peft_model, PeftConfig, PeftModel, prepare_model_for_kbit_training, TaskType
from transformers import TrainingArguments
from trl import SFTTrainer, DataCollatorForCompletionOnlyLM
Prepare the Dataset for Fine-Tuning
You can load the SamSum dataset directly using the [Hugging Face Datasets libraries](https://huggingface.co/docs/datasets/index via Python code:
dataset_name = "samsum"
dataset = load_dataset(dataset_name)
train_dataset = dataset['train']
eval_dataset = dataset['validation']
test_dataset = dataset['test']
dataset
The dataset contains a total of 14,732 samples for training, 818 samples for validation, and 818 samples for testing. A sample of the dataset is displayed below:
To format the original training dataset into prompts for instruction fine-tuning, you can use the following helper function. For more details, refer to the detailed reference here).
def formatting_prompts_func(example):
output_texts = []
for i in range(len(example['id'])):
instruction = "Summarize this Dialogue."
input = example['dialogue'][i]
output = example['summary'][i]
prompt="### Instruction:\n{instruction}\n\n### Dialogue:\n{input}\n\n### Summary:\n{output}".format(instruction=instruction, input=input, output=output)
output_texts.append(prompt)
return output_texts
Set up the Configuration for Fine-Tuning
To reduce VRAM usage during training, you will fine-tune a resharded version of Falcon-7B in 4-bit precision using QLoRA. You can use the following code snippet to load the base model and prepare it for the QLoRA experiment:
model_name = "vilsonrodrigues/falcon-7b-sharded"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.float16,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
Based on the QLoRA paper, we will taget all linear transformer block layers as target modules for fine-tuning (also see the discussions on reddit here). You can leverage the following helper function to find these target modules:
def find_target_modules(model):
# Initialize a Set to Store Unique Layers
unique_layers = set()
# Iterate Over All Named Modules in the Model
for name, module in model.named_modules():
# Check if the Module Type Contains 'Linear4bit'
if "Linear4bit" in str(type(module)):
# Extract the Type of the Layer
layer_type = name.split('.')[-1]
# Add the Layer Type to the Set of Unique Layers
unique_layers.add(layer_type)
# Return the Set of Unique Layers Converted to a List
return list(unique_layers)
target_modules = find_target_modules(model)
print(target_modules)
And in this case, the target modules for fine-tuning will be
['dense_4h_to_h', 'dense_h_to_4h', 'query_key_value', 'dense'].
After loading and preparing the base model for QLoRA, you can configure the fine-tuning experiment using the following code:
model = prepare_model_for_kbit_training(model)
lora_alpha = 32
lora_dropout = 0.1
lora_rank = 16
peft_config = LoraConfig(
lora_alpha=lora_alpha,
lora_dropout=lora_dropout,
r=lora_rank,
bias="none",
task_type="CAUSAL_LM",
target_modules=[
"query_key_value",
"dense",
"dense_h_to_4h",
"dense_4h_to_h",
]
)
peft_model = get_peft_model(model, peft_config)
peft_model.print_trainable_parameters()
This configuration will result in an adapter model with 32,636,928 trainable parameters, which is only 0.47% of the trainable parameters compared to the 6,954,357,632 parameters of the base model.
Set up the Configuration for Trainig
Load the tokenizer from the pre-trained base model, both the base model, the LoRA config, and the tokenizer will be needed for the SFT trainer.
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
if tokenizer.pad_token_id is None:
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
tokenizer.padding_side = "right"
Below is the configuration used for SFT
output_dir = "falcon_7b_LoRA_r16_alpha32_epoch10_dialogue_summarization_v0.1"
per_device_train_batch_size = 32 #4
gradient_accumulation_steps = 4
gradient_checkpointing=False
optim = "paged_adamw_32bit"
save_steps = 20
logging_steps = 20
learning_rate = 2e-4
max_grad_norm = 0.1
warmup_ratio = 0.01
lr_scheduler_type = "cosine" #"constant"
num_train_epochs = 5
seed=42
max_seq_length = 512
training_arguments = TrainingArguments(
output_dir=output_dir,
per_device_train_batch_size=per_device_train_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=gradient_checkpointing,
optim=optim,
save_steps=save_steps,
logging_steps=logging_steps,
learning_rate=learning_rate,
fp16=True,
max_grad_norm=max_grad_norm,
num_train_epochs=num_train_epochs,
warmup_ratio=warmup_ratio,
group_by_length=True,
lr_scheduler_type=lr_scheduler_type,
push_to_hub=True,
report_to="wandb"
)
trainer = SFTTrainer(
model=peft_model,
train_dataset=train_dataset,
formatting_func=formatting_prompts_func,
tokenizer=tokenizer,
peft_config=peft_config,
max_seq_length=max_seq_length,
args=training_arguments,
)
You can initiate the fine-tuning experiment via
trainer.train()
The entire training process took approximately 3 hours running on an A100 instance with a single GPU.
Model Inference of the Fined-Tuned Model
Upon completion of the training process, you can easily share the adapter model by uploading it to Hugging Face’s model repository using the following code:
trainer.push_to_hub()
This published adapter model can then be retrieved and used in conjunction with the base model for various summarization tasks, as demonstrated in the reference code snippet below.
PEFT_MODEL = "bearbearyu1223/falcon_7b_LoRA_r16_alpha32_epoch10_dialogue_summarization_v0.1"
config = PeftConfig.from_pretrained(PEFT_MODEL)
peft_base_model = AutoModelForCausalLM.from_pretrained(
config.base_model_name_or_path,
return_dict=True,
quantization_config=bnb_config,
device_map="auto",
trust_remote_code=True,
)
peft_model = PeftModel.from_pretrained(peft_base_model, PEFT_MODEL)
# Generate Summarization
def get_summary(dialogue, max_new_tokens=50, max_length=512, verbose=False):
prompt= "### Instruction:\n{instruction}\n\n### Dialogue:\n{dialogue}\n\n### Summary:\n".format(instruction="Summarize the Dialogue below.", dialogue=dialogue)
if verbose:
print(prompt)
peft_encoding = peft_tokenizer(prompt, truncation=True, return_tensors="pt").to(torch.device("cuda:0"))
peft_outputs = peft_model.generate(input_ids=peft_encoding.input_ids, generation_config=GenerationConfig(max_length=max_length, do_sample=True,
max_new_tokens=max_new_tokens,
pad_token_id = peft_tokenizer.eos_token_id,
eos_token_id = peft_tokenizer.eos_token_id,
attention_mask = peft_encoding.attention_mask,
temperature=0.1, top_k=1, repetition_penalty=30.0, num_return_sequences=1,))
peft_text_output = peft_tokenizer.decode(peft_outputs[0], skip_special_tokens=True)
sub = "### Summary:"
raw_summary = peft_text_output.split(sub)[1]
return raw_summary
See an example of a summary generated by the fine-tuned model in comparison to the reference summary crafted by a human below
test_index=6
dialogue=test_dataset[test_index]['dialogue']
summary=test_dataset[test_index]['summary']
peft_output=get_summary(dialogue,verbose=True)
print("Human Summary:")
print(summary)
print("PEFT Summary:")
print(peft_output)
| Instruction |
|---|
| Summarize the Dialogue below. |
Max: Know any good sites to buy clothes from?
Payton: Sure :) <file_other> <file_other> <file_other> <file_other> <file_other> <file_other> <file_other>
Max: That's a lot of them!
Payton: Yeah, but they have different things so I usually buy things from 2 or 3 of them.
Max: I'll check them out. Thanks.
Payton: No problem :)
Max: How about u?
Payton: What about me?
Max: Do u like shopping?
Payton: Yes and no.
Max: How come?
Payton: I like browsing, trying on, looking in the mirror and seeing how I look, but not always buying.
Max: Y not?
Payton: Isn't it obvious? ;)
Max: Sry ;)
Payton: If I bought everything I liked, I'd have nothing left to live on ;)
Max: Same here, but probably different category ;)
Payton: Lol
Max: So what do u usually buy?
Payton: Well, I have 2 things I must struggle to resist!
Max: Which are?
Payton: Clothes, ofc ;)
Max: Right. And the second one?
Payton: Books. I absolutely love reading!
Max: Gr8! What books do u read?
Payton: Everything I can get my hands on :)
Max: Srsly?
Payton: Yup :)
| Summary Type | Summary Description |
|---|---|
| Human | Payton provides Max with websites selling clothes. Payton likes browsing and trying on the clothes but not necessarily buying them. Payton usually buys clothes and books as he loves reading. |
| PEFT | Payton sends Max some links with online shops where she buys her stuff. Payton likes both fashion items and literature. She reads all kinds of fiction. |
Evaluation of Summarization Quality
Traditional evaluation methods for summarization tasks rely on metrics like ROUGE and BLEU, which evaluate the generated summaries by comparing them to human-written reference summaries. These metrics assess aspects such as the overlap in n-grams and word sequences, offering a quantitative and also automated assessment of summary quality.
In cases where human reference summaries are unavailable, it becomes imperative to establish well-defined and consistent annotation guidelines for human annotators. Below is a list of criteria we will consider when formulating the annotation guidelines.
Metric 1: Relevance
Capturing the Essence: The LLM will assist annotators in evaluating the relevance of a summary. Annotators will evaluate the relevance of a summary on a scale of 1 to 5 (higher score indicates better quality), considering whether the summary effectively extracts important content from the source conversation, avoiding redundancies and excess information. With clear criteria and steps, annotators can confidently assign scores that reflect the summary’s ability to convey essential details.
Metric 2: Coherence
Creating Clarity: The LLM will assist annotators in evaluating the coherence of a summary. Annotators will rate summaries from 1 to 5 (higher score indicates better quality), focusing on the summary’s organization and logical flow. Clear guidelines enable annotators to determine how well the summary presents information in a structured and coherent manner.
Metric 3: Consistency
Factually Sound: The LLM will assist annotators in evaluating the consistency of a summary. Annotators will assess summaries for factual alignment with the source conversation, rating them from 1 to 5 (higher score indicates better quality). SummarizeMaster ensures that annotators identify and penalize summaries containing factual inaccuracies or hallucinated facts, enhancing the reliability of the evaluation process.
Metric 4: Fluency
Language Excellence: The LLM will assist annotators in evaluating the fluency of a summary. Fluency is a critical aspect of summary evaluation. Annotators will assess summaries for grammar, spelling, punctuation, word choice, and sentence structure, assigning scores from 1 to 5 (higher score indicates better quality).
We will transform these instructions into a prompt template for input to GPT-3.5-turbo to assess the quality of the summaries generated by our fine-tuned model (check out this Colab to run the evaluation). This approach is primarily motivated by the goal of achieving consistency, standardization, and efficiency in the manual evaluation process, which can otherwise be labor-intensive.
Lessons Learned
The automated evaluation results for the 818 test samples are shared here. Simple statistical analysis reveals that the fine-tuned LLM demonstrated a reasonable level of performance on the test set when compared to the human-generated summaries (refer to the chart below)
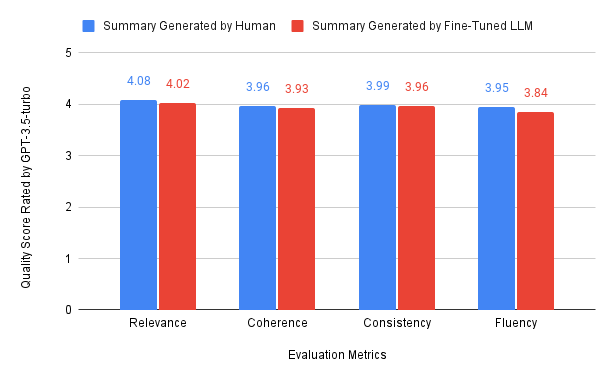
However, is that truly the situation? Let’s examine a few instances together.
Example 1:
Yaz: Hi babes, you off out Friday, I need to get my freak on!
Tania: Why the hell not, college work is really doing my head in with the deadlines!
Yaz: Seen Sophie lately, her and lover boy are looking well serious!
Tania: Yeah, saw her in the canteen a couple of days ago, she's thinking of breaking up before Uni. Cutting ties etc
Yaz: Well, maybe not so serious after all then!
Tania: Best to go there single, in my opinion!
Yaz: Yeah, not got much choice in the matter. Maybe I'll meet my dream woman there!😀
Tania: Why the hell not?! I can't wait to get out of here and up to Manchester, only 4 months and a bit, now!
Yaz: Christ, that came around quick, just the little matter of A Levels and getting into Exeter to deal with. I need such high grades for my course, medicine is a cut-throat world.
Tania: Hope not! If anyone is suited to becoming a Dr love, it's you, I am positive of it!
Yaz: Hope you're right, babes! Anyway, pub Friday at 8ish?
Tania: Hell, yes! See you!
| Summary - Human Baseline | Summary - PEFT Baseline | Relevance Human |
Relevance PEFT Model |
Coherence Human |
Coherence PEFT Model |
Consistency Human |
Consistency PEFT Model |
Fluency Human |
Fluency PEFT Model |
|---|---|---|---|---|---|---|---|---|---|
| Yaz and Tania will go to a pub on Friday around 8. Sophie is thinking of breaking up with her boyfriend before Uni. Tania is going to Manchester in 4 months. Yaz wants to study medicine in Exeter, so she needs high grades. | Sophie wants to break up because he boyfriend has been cheating on him. Tania needs good results from exams to be admitted to university. Yaz will see his friends at the bar tonight about 8 pm. | 4 | 3 | 4 | 3 | 4 | 2 | 4 | 2 |
Learnings: The LLM-based evaluator is capable of performing a reasonably accurate evaluation. In this example, it appears that the summary generated by the fine-tuned model does not align with the factual content of the source conversation. The original source conversation does not mention that Sophie’s boyfriend is cheating. Furthermore, there is a factual inaccuracy in the summary, as it is Yaz, not Tania, who requires a high score for admission to Exeter for studying medicine. Additionally, there are some grammar errors that can be improved or corrected as suggested below (e.g., one can further prompt LLM and ask suggestions to improve the fluency of the summary):
-
“Sophie wants to break up because he boyfriend has been cheating on him.” Correction: “Sophie wants to break up because her boyfriend has been cheating on her.”
-
“Tania needs good results from exams to be admitted to university.” Correction: “Tania needs good exam results to be admitted to university.”
-
“Yaz will see his friends at the bar tonight about 8 pm.” Correction: “Yaz will see his friends at the bar tonight at about 8 pm.”
These quality issues have been identified by the LLM-based evaluator, which rated both consistency and fluency as 2.
Example 2:
Petra: I need to sleep, I can't stand how sleepy I am
Andy: I know, and it's so boring today, nobody's working at the office
Ezgi: I am working! lazy pigs
Petra: I'm sleeping with my eyes open, kill me
Andy: ask the fat woman from HR
Petra: she would kill me on spot without batting an eye
Andy: she always repeats she has a black belt in karate
Petra: it's hard to believe she can move, but let her have whatever belt she wants
Andy: LOL
Petra: sooooo sleepy
| Summary - Human Baseline | Summary - PEFT Baseline | Relevance Human |
Relevance PEFT Model |
Coherence Human |
Coherence PEFT Model |
Consistency Human |
Consistency PEFT Model |
Fluency Human |
Fluency PEFT Model |
|---|---|---|---|---|---|---|---|---|---|
| Petra is very sleepy at work today, Andy finds the day boring, and Ezgi is working. | It is difficult for Petra not to fall asleep because of being tired. Andy suggests that Petra should talk about this issue with the lady who works as human resources manager. She might be able to help Petra. | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
Learnings: LLM-based evaluators may not always accurately capture the intended context or nuances from the conversation. In this example, the human-generated summary outperforms the summary generated by the fine-tuned model. Interestingly, neither the fine-tuned model’s generated summary nor the LLM-based evaluator were able to accurately recognize the sarcasm conveyed in the original conversations, particularly with reference to the “HR lady”.
Example 3:
Finn: Hey
Zadie: Hi there! What's up?
Finn: All fine. You?
Zadie: Not bad, thanks
Finn: Look, I was thinking of going to this neighborhood called Elephant and Castle tomorrow, it's apparently full of Latin American stuff. Fancy joining?
Zadie: Sure! But what's ""stuff""? 😂
Finn: lol So apparently it's a place were random people from ""Latin America"" (meaning fuck knows which countries) started running small businesses and restaurant, and a nice little community was formed
Zadie: Oh cool
Finn: Then capitalism came and it's all going to be demolished soon, so it's like the last chance to go
Zadie: What a shame :( Yeah, I haven't had Latin American 😂 food for ages so I'm totally up for it
Finn: Can't wait to taste this cuisine of unspecified Latino origin lol
Zadie: 😂😂😂
Finn: But we can specify time and place if and only if you wish
Zadie: I might be tempted to lol I'd say early evening, 2-ish?
Finn: Yeah, that's fine by me. So most of the places we want to visit are in this Elephant and Castle shopping centre. Shall I see you at the main entrance, wherever that is
Zadie: 2 o'clock at unspecified main entrance then? Sounds good to mw
Finn: Yer
Zadie: Cool, see you there! And thanks so much for remembering about me 💜💜💜
Finn: Thanks for saying yes to such an ill-defined plan lmao
Zadie: Ha ha You know I love those
Finn: See you tomorrow then
Zadie: Yep Call me if you get lost
Finn: I will I will 🤙 byeeee
Zadie: Toodles
| Summary - Human Baseline | Summary - PEFT Baseline | Relevance Human |
Relevance PEFT Model |
Coherence Human |
Coherence PEFT Model |
Consistency Human |
Consistency PEFT Model |
Fluency Human |
Fluency PEFT Model |
|---|---|---|---|---|---|---|---|---|---|
| Finn and Zadie are going to Elephant and Castle tomorrow at 2. They will meet at the main entrance. | Tomorrow Finn wants Zadie join him on his trip around London. They meet at 2 pm near the elephant statue outside the Elephant and Castle Shopping Centre. The neighbourhood has been created by immigrants from South America. | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
Learnings: Both the fine-tuned LLM model and the LLM-based evaluator may occasionally treat context derived from their pre-learned world knowledge as factual information. This underscores the importance of exercising caution when incorporating inferred contextual information into the product experience. In this example, the summary generated by the fine-tuned model is considered to yield “impressive results” because it correctly identifies that “Elephant and Castle” is a place of interest located in London, and it recognizes the presence of an elephant statue near the entrance to the shopping center, both of which are not directly mentioned in the original conversation. Those additional context is derived from the base model’s world knowledge from training.
However, it raises questions about whether we should deem this as a good summary when the LLM leverages its world knowledge to infer information beyond the direct content of the conversation. It’s important to acknowledge that this approach can be a double-edged sword from a product experience perspective. Some users may find it useful and intelligent as it demonstrates the LLM’s ability to provide context and additional information. Still, it can also potentially be problematic in many situations.
Here are some considerations:
-
Cultural Variations and Sensitivity: Inferring information based on world knowledge can be problematic when dealing with culturally sensitive topics or diverse audiences. Assumptions made by the model may not align with cultural variations or norms, potentially leading to misunderstandings or offense.
-
Privacy and Ethical Concerns: Inferences based on world knowledge can sometimes delve into personal or sensitive areas, raising ethical concerns.
-
Accuracy and Context: While the model’s inferences may be impressive, they may not always accurately capture the intended context or nuances since the world knowledge can be updated, and the model may be trained on outdated data. This can result in potential inaccuracies when applying such knowledge to generate summaries.
-
Users’ Preferences and Control: Users’ preferences for summaries may vary. Some may appreciate the additional context provided by model inference, while others may prefer more straightforward and direct summaries. It’s essential to provide users with transparency and control over how additional context is used to generate summaries. Users should have the option to enable or disable such contextual inferences to align with their preferences.
My Top 3 Takeaways from this Intriguing Project!
-
Fine-Tuning LLM through adaptation has demonstrated itself as an exceptionally efficient and cost-effective method for developing LLM-powered product experiences. It allows companies, even those not creating their own foundation models, to harness this approach and benefit from the latest and most advanced outcomes driven by Generative AI.
-
Leveraging the world knowledge acquired by the base model can indeed lead to “impressive results” for the fine-tuned model. However, it’s essential to bear in mind that this can be a double-edged sword!
-
LLM can serve as a referee much like a human, evaluating generation results from another LLM or a fine-tuned model. Nevertheless, exercise caution when depending on an LLM-based evaluator to shape your product experience, as not all evaluations may be equally reliable!
I hope my insights resonate with your experience as well!