Build On-Device QnA with LangChain and Llama2
TL;DR
This post involves creating a Question and Answering system using the LLM model hosted on Apple M1 Pro. The key building blocks include the LLM model (llama-2-7b-chat.ggmlv3.q8_0.bin), an embedding model (sentence-transformers/all-MiniLM-L6-v2), and an on-device vector database (FAISS). The app is built using the “LangChain” framework. All components are open source, eliminating the need for OpenAI services. The system’s performance is similar to OpenAI but with 10x longer latency (around 60s/query vs 5s/query) due to on-device model inference.
Introduction
Third-party commercial large language model (LLM) providers, such as OpenAI’s GPT-4, Google Bard, and Amazon AlexaTM, have greatly democratized access to LLM capabilities through seamless API integration and scalable model inference hosting in the cloud. These advanced LLMs possess the remarkable ability to comprehend, learn from, and produce text that is nearly indistinguishable from human-generated content. Beyond their text generation prowess, these LLMs excel in interactive conversations, question answering, dialogue and document summarization, as well as offering insightful recommendations. Their versatility finds applications across diverse tasks and industries including creative copywriting for marketing, precise document summarization for legal purposes, data-driven market research in the financial sector, realistic simulation of clinical trials within healthcare, and even code generation for software development.
However, certain scenarios, driven by an increasing emphasis on safeguarding data privacy and adhering to stringent regulatory compliance standards, highlight the necessity of deploying LLMs on private hardware devices instead of on any of those third-party owned servers. In such instances, maintaining sensitive information within the confines of the user’s hardware not only mitigates the risks associated with data breaches and unauthorized access but also aligns with the evolving landscape of privacy-conscious technical practices. This approach fosters a sense of trust among users who are becoming more attuned to the importance of maintaining their personal information within their own environments.
In this post, our focus lies in exploring the execution of quantized variants of open-source Llama2 models on local devices to achieve Retrieval Augmented Generation (RAG). For RAG powered by server-side LLMs, you can find more info in my previous post.
Llama2 and Its variants
Llama 2, launched by Meta in July 2023, has been pretrained on publicly available online data sources, encompassing a staggering 2 trillion tokens with a context length of 4096. The subsequent supervised fine-tuned iteration of this model, known as Llama-2-chat, underwent meticulous refinement through the integration of over 1 million human annotations to cater specifically to chat-oriented use cases. Meta has extended the accessibility of Llama 2 to a wide spectrum of users, ranging from individual developers and content creators to researchers and businesses. This strategic open-source initiative is aimed at fostering an ecosystem conducive to Responsible AI experimentation, innovation, and the scalable implementation of a diverse array of ideas, thus further democratizing Generative AI.
Llama 2 is offered in an array of parameter sizes — 7B, 13B, and 70B — alongside both pretrained and fine-tuned variations to cater to a wide range of application needs.
Framework and Libraries Used: LangChain, GGML, C Transformers
LangChain is an open source framework for developing applications powered by LLMs. It goes beyond standard API calls by being data-aware, enabling connections with various data sources for richer, personalized experiences. It is also agentic, meaning it can empower a language model to interact dynamically with its environment. LangChain streamlines the development of diverse applications, such as chatbots, Generative Question and Answering (GQA), and summarization. By “chaining” components from multiple modules, it allows for the creation of unique applications built around an LLM with easy-to-code and fast-to-production developer experience.
GGML is a C library for machine learning (ML). GGML makes use of a technique called “quantization” (e.g., convert LLM’s weights from high-precison floating numbers to low-precision floating numbers) that allows for large language models to run on consumer hardware. GGML supports a number of different quantization strategies (e.g. 4-bit, 5-bit, and 8-bit quantization), each of which offers different trade-offs between efficiency and performance. More information about these trade-offs (such as model disk size and inference speed) can be found in the documentation for llama.cpp.
C Transformers is a wrapper that provides the Python bindings for the Transformer models implemented in C/C++ using GGML. C Transformers supports running Llama2 model inference via GPU, for both NVIDIA GPU (via CUDA, a programming language for NVIDIA GPUs) and Apple’s own integreated GPU and Neural Engine (via Metal, a programming language for Apple integrated GPUs).
Note: To use C transformers with Metal Support for model inference running on Apple M1/M2 chip, need run the following cmd under your project root
poetry config --local installer.no-binary ctransformers
poetry add ctransformers
Retrieval Augmented Generation
Retrieval Augmented Generation (RAG) represents a technique wherein data is retrieved from external sources to enhance and expand the prompts used in model generation. This method is not only a cost-effective alternative but also proves to be an efficient approach in comparison to the traditional methods of pre-training or fine-tuning foundation models. See the previous post at Food QnA Chatbot : Help Answer Food Related Questions from Your Own Cookbook as a brief into to RAG.
An Example Project
The source code for the example project can be found on ![]() . The project directory should look like below:
. The project directory should look like below:
food_qna_on_device
├── README.md
├── build_knowledge_base.py
├── config.py
├── cook_book_data
│ ├── GCE-Dinner-in-30-EXPANDED-BLAD.pdf
│ ├── Quick-Easy-Weeknight-Meals-1.pdf
│ └── dinners_cookbook_508-compliant.pdf
├── main.py
├── models
│ ├── llama-2-13b-chat.ggmlv3.q8_0.bin
│ └── llama-2-7b-chat.ggmlv3.q8_0.bin
├── poetry.lock
├── poetry.toml
├── pyproject.toml
└── vector_db
├── index.faiss
└── index.pkl
Instruction to run the example project:
- Step 1: Launch the terminal from the project directory, install and resolve the dependencies as defined in
pyproject.tomlfile viapoetry install - Step 2: Download the quantized 7b model
llama-2-7b-chat.ggmlv3.q8_0.binfrom https://huggingface.co/TheBloke/Llama-2-7B-Chat-GGML and save the model under the directorymodels\ - Step 3: To start parsing user queries into the application, run the following command from the project directory (note: the model inference can take ~1 mins per input query)
poetry run python main.py -c localOptionally, to run the same query with OpenAI (note: the model inference will take a few seconds per input query, you will also need export OPENAI_API_KEY as an enviroment variable on your local dev machine)
poetry run python main.py -c server - Step 4: Enter a query related to food preparation and cooking into the console and start playing with it.
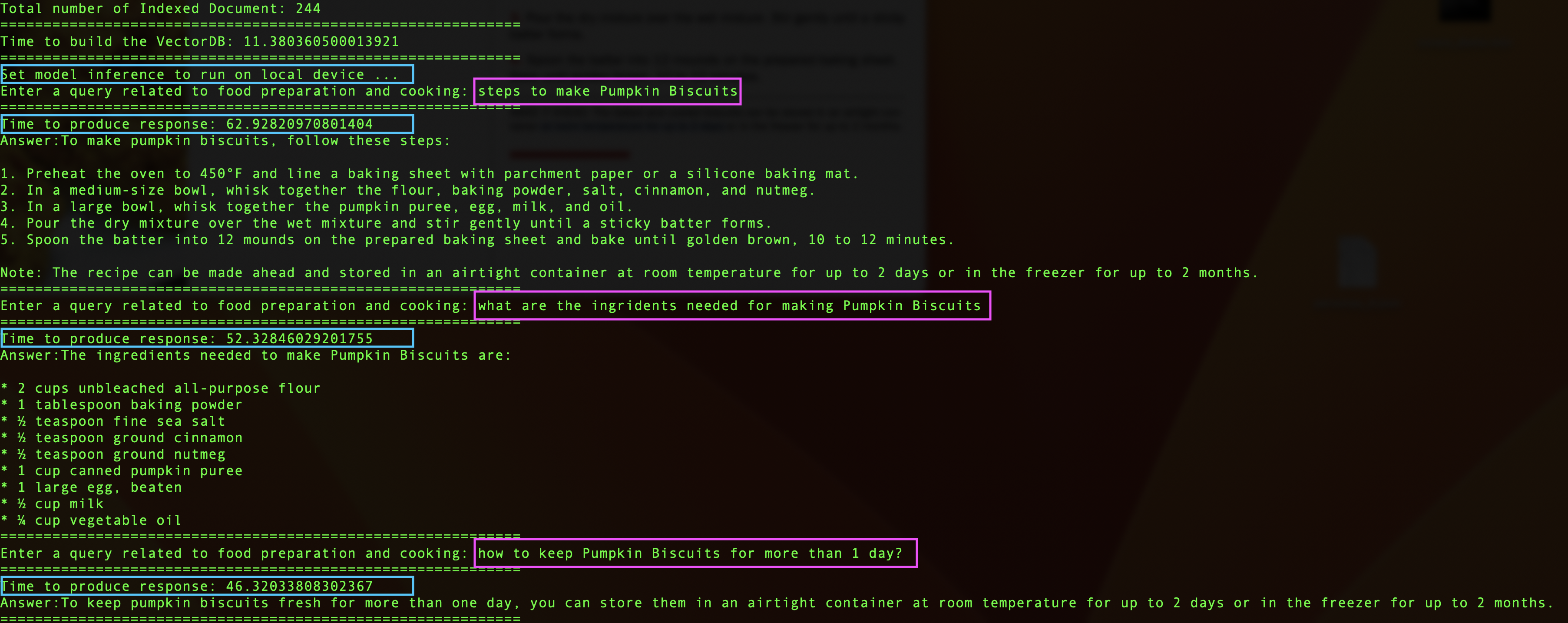
See an example below:
Screenshot of the original content for making “Pumpkin Biscuits”.
 Retrieval Augmented Generation by running Llama2 model inference on local device
Retrieval Augmented Generation by running Llama2 model inference on local device