Pepper & Carrot AI-powered flipbook · Part 16 — Deploying an LLM App Without a GPU: A Managed-API Stack on Anthropic + Voyage
Post 16 of the Pepper & Carrot AI flipbook series — the alternative deploy. Post 14 put the reading companion on five clouds with a Modal GPU serving Ollama, because the series is about local-first inference. This post takes the same app and ships it without a GPU at all: chat on the Anthropic Messages API, embeddings on Voyage AI. The whole point is that it's a *configuration* change, not a code change — the provider abstraction from Post 4 was built for exactly this, and the only new code in the repo is documentation. The interesting parts are the trade the swap makes (cost and latency for the local-first thesis) and the one real gotcha nobody warns you about: a managed embeddings model lives in a different vector space, so the search index has to be rebuilt before the first deploy or retrieval silently returns garbage.
Post 16 of the Pepper & Carrot AI-powered flipbook series. Posts 14–15 shipped the reading companion to the public internet on five services: Cloudflare Pages, Fly.io, Neon, Cloudflare R2, and Modal, the serverless GPU that runs Ollama serving qwen2.5:7b and bge-m3. That GPU is the soul of the series’ thesis, local-first inference on commodity hardware. It’s also the single most expensive, most operationally involved, and slowest-to-wake piece of the whole deploy. This post is for the reader who looks at that GPU and asks the reasonable question: do I actually need it?
For a lot of portfolio cases, no. If you don’t care that the model runs on hardware you control, and you’d rather have a faster first answer, a near-zero bill, and two fewer things to operate, you can swap the entire AI layer for two hosted APIs and never touch a GPU. Chat moves to the Anthropic Messages API; embeddings move to Voyage AI. And here’s the part that’s actually the point of the post: doing this requires no new application logic. Not a line of the orchestration, retrieval, or client code changes. The swap is two environment variables and one re-index (plus, in this repo, bumping the default chat and embedding models to the current recommended pair, which the env template sets explicitly anyway). That it’s that small is no accident — it’s the Post 4 provider abstraction finally being asked to do the thing it was designed for, a second time.
▶ Try it live: pepper-carrot-ai-flipbook.devcloudweb.com — this is the exact deploy this post describes, running right now: chat on the Anthropic API, embeddings on Voyage, everything else on Cloudflare Pages + Fly + Neon + R2. Pick an episode, ask the companion who’s on the page or about Hereva’s lore, and watch the answer stream in token by token. Because there’s no GPU to cold-start, the first answer is quick — though if the Fly backend has scaled to zero you may wait a few seconds for it to wake. Pepper & Carrot is © David Revoy, CC BY 4.0.
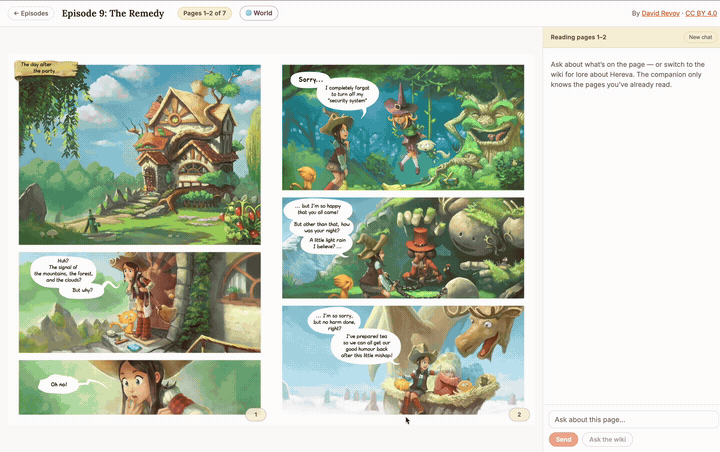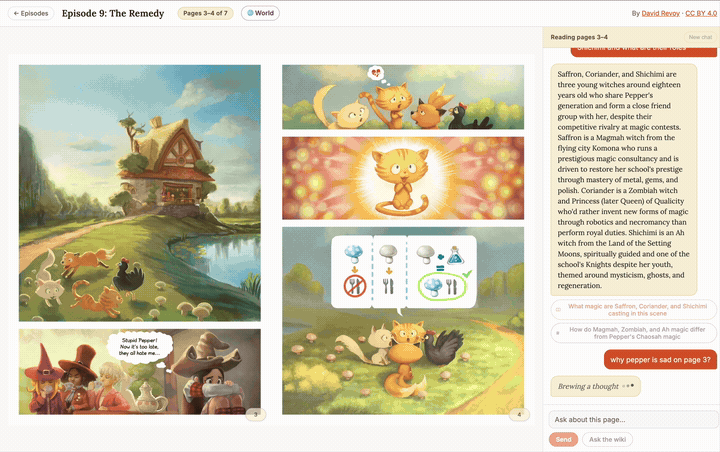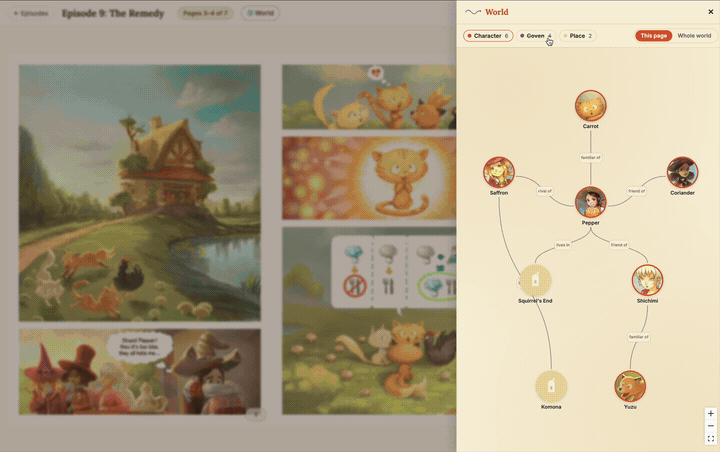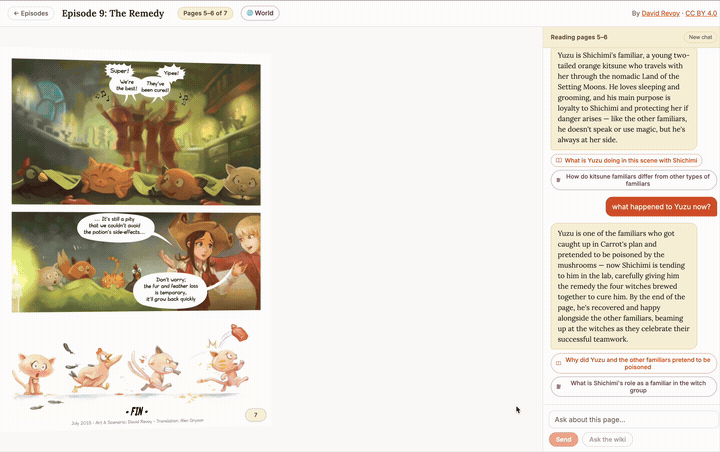
The deployed companion in action — the StPageFlip flipbook plus the spoiler-safe streaming chat, all running on the Anthropic + Voyage path (recording condensed ~3×). Click to enlarge.
What you’ll build in this post.
- The same deployed app as Posts 14–15, minus the GPU. Cloudflare Pages + Fly + Neon + R2 are unchanged; the Modal tier is replaced by the Anthropic Messages API (chat) and the Voyage AI API (embeddings). No
modal deploy, no model-weights volume, no proxy-auth tokens, no GPU cold start.- A config-only provider swap.
CHAT_PROVIDER=anthropicselects theAnthropicChatClientthat already lives inbackend/app/clients/chat.py;EMBEDDING_PROVIDER=voyageselects theVoyageEmbeddingClientinbackend/app/clients/embedding.py. The factory inbackend/app/clients/__init__.pyalready carries both branches. The only code this post changes is two default-model strings (toclaude-haiku-4-5andvoyage-4-lite); everything else it adds is documentation.- A dedicated env template (
.env.production.anthropic.example) so you copy-and-fill instead of uncommenting a block.- A standalone deploy guide (
docs/deployment-anthropic.md) — the full step-by-step for this path, with a troubleshooting table for the failure modes specific to it.- An ADR (
docs/decisions/0005-managed-api-alternative.md) capturing the decision and the trade it makes.- The one real gotcha, handled: because a Voyage embedding lives in a different vector space than a
bge-m3embedding, the local search index has to be rebuilt before deploy. Skip it and retrieval fails silently. The guide makes it a hard Step 2.Prerequisites.
- You’ve shipped — or at least read — Posts 14–15. This post is a fork of that deploy, not a from-scratch one; it reuses Neon, R2, Fly, and Pages verbatim and only re-explains the AI layer.
- The workshop starter at the
post-16-managedtag:git checkout post-16-managed. The app running locally end-to-end (at least Episode 1 ingested, the wiki ingested, chat + flipbook working atlocalhost:5173).- Free accounts on Fly.io, Neon, and Cloudflare (same as Posts 14–15), plus Anthropic Console and Voyage AI. No Modal account.
- CLIs:
brew install flyctl rclone. (Nomodalthis time.)
About the repo URL. Everything new in this post — the env template, the standalone guide, and the ADR — lives in the same workshop starter that’s backed every post, now tagged
post-16-managed. TheAnthropicChatClientandVoyageEmbeddingClientthemselves shipped earlier (Post 11 wired up the Anthropic swap-in; the Voyage client landed with the cloud work atpost-14-15-deploy), which is exactly why this post changes no client or orchestration logic — only documentation and two default-model strings. File links below point at thepost-16-managedtag.
Table of Contents
- The Fork in the Road
- What Actually Changes — and What Pointedly Doesn’t
- Two Managed APIs, in Plain English
- The One Real Gotcha: Re-indexing the Vector Space
- The Cost & Latency Ledger
- Deploy It: The Three Deltas
- The
fly.tomlTrap:[env]vs. Secrets - What’s Honest, What’s Open
- Key Takeaways
- Which Path Should You Ship?
The Fork in the Road
The series has had one consistent thesis: you can build a genuinely good AI product on hardware you control, with open models, for the price of a coffee a month. Post 14 is the cloud expression of that. Modal allocates a real GPU only while a question is being answered, runs qwen2.5:7b, and releases it. At portfolio traffic that costs ~$5–10/month, almost all of it GPU seconds.
But a thesis is a constraint, and constraints have a cost. The GPU is responsible for nearly every rough edge in the Posts 14–15 deploy:
- It’s the expensive tier (~$5–10/mo; everything else is free).
- It’s the slow tier: the first question after idle waits 15–30 seconds for Modal to allocate a GPU and load 6 GB of weights into VRAM. That’s the cold start the whole “The First Cold Start Is the Demo” section of Post 15 had to choreograph around.
- It’s the operationally heaviest tier: a
modal deploy, a persistent weights volume, and a pair of proxy-auth tokens to keep the endpoint from being a public bill-runner.
If the local-first thesis is the point of your portfolio piece — if the story you’re telling a reviewer is “I can serve my own models” — then all of that is worth it, and you should ship the Posts 14–15 path. But if the thesis isn’t load-bearing for you, every one of those costs evaporates the moment you hand the model off to someone whose entire business is running it well. That’s the fork:
- Keep the GPU (Posts 14–15): self-hosted, private, on-thesis. ~$5–10/mo, 15–30 s cold start, one more service to run.
- Skip the GPU (this post): managed APIs, instant, off-thesis. ~$0.10/mo, no GPU cold start, two API keys to manage.
Neither is “correct.” They optimize for different things, and being able to articulate which one you’d pick and why is itself the portfolio signal — more than the deploy mechanics on either side. This post builds the second path and is honest about what it trades away to get there.
What Actually Changes — and What Pointedly Doesn’t
Here’s the whole change, as a mental diff. Start with what doesn’t move, because that’s the surprising part:
- The orchestration layer (
backend/app/orchestration/chat.py) is unchanged. It calls aChatClientand anEmbeddingClientthrough their Protocols and has no idea what’s behind them. - The retrieval layer (
backend/app/retrieval/service.py), including the spoiler boundary, is unchanged. It asks anEmbeddingClientfor a query vector and queries Chroma; it doesn’t care who computed the vector. - The prompts (
backend/app/core/prompts.py) are unchanged. The Post 11 hardening that taught a small model to be concise and stay grounded still applies; a bigger model just clears the bar more easily. - The API surface, the frontend, the database schema, the image storage are all unchanged.
What moves is two strings in the environment:
1
2
3
4
5
6
7
# Before (Posts 14–15, the Modal path):
CHAT_PROVIDER=ollama # → OllamaChatClient, pointed at the Modal URL
EMBEDDING_PROVIDER=ollama # → OllamaEmbeddingClient, same Modal URL
# After (this post, the managed-API path):
CHAT_PROVIDER=anthropic # → AnthropicChatClient
EMBEDDING_PROVIDER=voyage # → VoyageEmbeddingClient
Those strings are read by a factory that’s existed since Post 4. Here’s the actual code that does the dispatch, and note that adding the managed-API path required adding branches, not changing callers:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# backend/app/clients/__init__.py — the factory, abbreviated
def get_chat_client(settings: Settings) -> ChatClient:
if settings.chat_provider == "ollama":
return OllamaChatClient(base_url=settings.ollama_base_url, ...)
if settings.chat_provider == "anthropic":
return AnthropicChatClient(
api_key=settings.anthropic_api_key,
model=settings.anthropic_model,
)
raise ValueError(f"Unknown chat_provider: {settings.chat_provider}")
def get_embedding_client(settings: Settings) -> EmbeddingClient:
if settings.embedding_provider == "sentence-transformers":
return SentenceTransformersEmbeddingClient(model=settings.embedding_model)
if settings.embedding_provider == "ollama":
return OllamaEmbeddingClient(base_url=settings.ollama_base_url, ...)
if settings.embedding_provider == "voyage":
return VoyageEmbeddingClient(
api_key=settings.voyage_api_key,
model=settings.voyage_model,
)
raise ValueError(f"Unknown embedding_provider: {settings.embedding_provider}")
Plain-English aside: what a “provider abstraction” buys you. Back in Post 4 the series spent a whole post insisting that the chat model, the embedding model, and the image store each be hidden behind a small interface (a Python
Protocol) — a contract that says “anything claiming to be aChatClientmust have astream()method,” without saying who implements it. The bet was that the implementation of those three things would change between a laptop and a cloud, and that nothing else should have to notice. This post is the bet paying out. The orchestrator was written againstChatClient, not against Ollama, so pointing it at Anthropic is a factory branch and an env var. The orchestrator’s source doesn’t change, doesn’t get recompiled, doesn’t even get re-read by a human. A good seam is one you can swap across without opening the file on the other side of it.
The diagram below is the entire architectural story of this post: one box on the right swaps out, and the colored seam it sits behind — the Post 4 ChatClient / EmbeddingClient Protocols — is exactly what makes the swap a no-code change.
The same backend, the same seam, one box swapped. Click the diagram to open it full-size in a new tab.
Two Managed APIs, in Plain English
Two providers replace the one Modal endpoint. If you’ve never used either, here’s what they are and why these two specifically.
The Anthropic Messages API is the hosted home for Claude. You POST a system prompt plus a list of messages to api.anthropic.com/v1/messages, and you get back the model’s reply, streamed token by token if you ask for it, which is exactly what the chat panel needs. There’s no model to download, no GPU to allocate, no cold start from your side; Anthropic keeps the hardware warm and you pay per token of input and output. The workshop’s AnthropicChatClient already speaks this protocol. It landed in Post 11 as the swap-in target, and it does one nice thing worth calling out: it sets prompt caching (cache_control: ephemeral) so that across a multi-turn conversation the repeated prefix — system prompt, page context, earlier turns — is cached and billed at roughly a 90% discount on the second turn onward. We default to claude-haiku-4-5, the cheapest current model, because the answers here are short and grounded in retrieved text; Haiku clears that bar comfortably.
Voyage AI is an embeddings API, and it’s Anthropic’s recommended embeddings partner, which is why it’s the natural pairing. You POST a batch of texts to api.voyageai.com/v1/embeddings and get back one vector per text. That’s the only job it does, and it does it without any infrastructure on your side. We use voyage-4-lite, which produces 1024-dimensional vectors at roughly $0.02 per million tokens, and Voyage’s free tier currently includes 200 million tokens, so at portfolio traffic the embeddings are not merely cheap but genuinely free. The workshop’s VoyageEmbeddingClient is about 80 lines: a thin POST, a defensive re-sort of the response by index (so a future API change can’t silently scramble which vector belongs to which document), and a set of mocked unit tests that keep the suite offline and deterministic.
Plain-English aside: why you still need embeddings at all. It’s tempting to think “I’m using a big hosted chat model now, surely it handles everything.” It doesn’t — and understanding why is the heart of retrieval-augmented generation. When a reader asks “who’s on this page?”, the app doesn’t send the whole comic to the chat model. It first finds the handful of relevant chunks — this page’s description, the right wiki entry — and sends only those. Finding them is a search problem, and the search works by turning both the question and every chunk into vectors (embeddings) and measuring which are closest in number-space. That search happens on every single question, regardless of which chat model answers it. So “skip Modal” can’t mean “drop embeddings” — it means “find an embeddings home that isn’t Modal.” Voyage is that home.
The One Real Gotcha: Re-indexing the Vector Space
Everything above makes this sound frictionless. There’s exactly one piece of friction, and it’s the kind that fails silently if you don’t know about it, which makes it worth its own section.
Your local search index (data/chroma, holding the pages_v1 and wiki_v1 collections) was built with bge-m3, which produces 1024-dimensional vectors. Voyage’s voyage-4-lite also produces 1024-dimensional vectors by default. So the two indexes are the same shape, and that’s exactly the trap. It’s tempting to reason “same number of dimensions, so they’re interchangeable.” They are not: two different embedding models place their vectors in two different, incompatible coordinate systems, and matching the number of dimensions does nothing to make those systems agree.
Plain-English aside: what “vector space” means and why same-size vectors still don’t mix. An embedding model is trained to lay text out in a high-dimensional space so that “similar meaning” becomes “physically close.” But where it puts any given sentence is an artifact of how that specific model was trained — there’s no universal map. Think of two cartographers who each draw a map of the same city on the same size sheet of graph paper — but one puts the origin at the cathedral and the other at the train station, and they rotate their axes differently. Both maps are internally consistent; distances within one map are meaningful. But a coordinate read off one map and plotted on the other points at a random rooftop — and the fact that both sheets are the same size doesn’t help one bit.
bge-m3andvoyage-4-liteare those two cartographers, both working at 1024 dimensions. A query vector from Voyage, compared against page vectors from bge-m3, measures nothing — the “nearest” chunks come back in essentially random order. (If you dialedvoyage-4-litedown to a 512-dimension output, you’d also have a size mismatch on top — but the size was never what made them incompatible.)
The insidious part is the failure mode. It doesn’t crash. Retrieval still returns some chunk IDs, the grounding text still loads from Postgres, the chat model still produces a fluent answer. It’s just that the chunks it was handed are unrelated to the question, so the answer drifts back to the model’s general knowledge — the dreaded “Pepper is a SoftBank robot” hallucination from the Posts 14–15 troubleshooting table. The tell-tale sign: the done SSE frame lists a non-empty retrieved_doc_ids, but the answer ignores the comic. Retrieval ran; it just ranked on noise.
So before deploying, you rebuild the index locally with Voyage. Postgres (the canonical text) and R2 (the image bytes) don’t depend on the embedder, so they stay exactly where they are — only Chroma rebuilds:
Run the rebuild in a shell where you haven’t
sourced.env.production. That file’sset -a && source …exports your NeonDATABASE_URL_OVERRIDE(with?sslmode=require) into the environment, and pydantic-settings prefers env vars over the.envfile — so the local re-index would aim at Neon instead of localhost and fail withTypeError: connect() got an unexpected keyword argument 'sslmode'(the ingestion engine has no asyncpg SSL shim). Fresh terminal, orunset DATABASE_URL_OVERRIDEfirst. The re-index must hit your local Postgres so the seed you dump later matches the new Chroma.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 1. Point local .env at Voyage.
echo 'EMBEDDING_PROVIDER=voyage' >> .env
echo 'VOYAGE_API_KEY=pa-...' >> .env
echo 'VOYAGE_MODEL=voyage-4-lite' >> .env
# 2. Wipe the bge-m3 collections.
rm -rf data/chroma
# 3. Rebuild pages_v1 for EVERY ingested episode — no slug list to maintain.
# Episodes live in data/raw/ep*/ (wiki dirs don't match `ep*`), and the
# wrapper maps a slug back to data/raw/<slug>, so each dir's basename IS the
# slug. The page-description JSONs already exist on disk, so nothing is
# re-described; only the embeddings (and Chroma) rebuild. `find` keeps this
# identical in bash and zsh (zsh has no `shopt -s nullglob`).
find data/raw -maxdepth 1 -type d -name 'ep*' | sort | while read -r dir; do
slug=$(basename "$dir")
echo "── re-indexing $slug ──"
.claude/skills/ingest-from-images/scripts/reingest_with_json.sh "$slug"
done
# 4. Rebuild wiki_v1 from the wiki summaries.
cd ingestion && uv run python ingest_wiki.py
Now, how do you confirm the rebuild landed in Voyage’s space? Here’s where the matched dimensions bite back: you can’t tell by looking at the index’s shape. A count-and-dimension peek is still worth running as a “did it build at all” sanity check —
1
2
3
4
5
6
7
8
9
10
11
12
cd backend && uv run python -c "
import chromadb
c = chromadb.PersistentClient(path='../data/chroma')
for name in ('pages_v1', 'wiki_v1'):
col = c.get_collection(name)
got = col.get(limit=1, include=['embeddings']) # get() needs an explicit include
embs = got['embeddings']
dim = len(embs[0]) if embs is not None and len(embs) else 0
print(f'{name}: {col.count()} chunks, dim={dim}')
"
# pages_v1: N chunks, dim=1024
# wiki_v1: M chunks, dim=1024
— but dim=1024 is what both embedders produce, so this proves the index is non-empty and well-formed, not that it’s Voyage’s. Two things give real confidence. First, the rebuild can’t quietly use the wrong embedder, because you set EMBEDDING_PROVIDER=voyage and the ingestion factory raises if VOYAGE_API_KEY is missing — a rebuild that completed, completed by calling Voyage. Second, and authoritatively, a grounded answer is the only proof that query-space and index-space agree. Embed a probe query exactly the way retrieval will and check the nearest chunk is sane:
1
2
3
4
5
6
7
8
9
10
11
12
cd backend && uv run python -c "
import asyncio, chromadb
from app.config import get_settings
from app.clients import get_embedding_client
client = get_embedding_client(get_settings()) # EMBEDDING_PROVIDER=voyage
vec = asyncio.run(client.embed_batch(['Who is Pepper and where does she live?']))[0]
col = chromadb.PersistentClient(path='../data/chroma').get_collection('wiki_v1')
hit = col.query(query_embeddings=[vec], n_results=1, include=['documents'])
print(hit['documents'][0][0][:200])
"
# Want: a Pepper/Hereva snippet. Gibberish or an unrelated entity = the query
# embedder and the stored vectors disagree → re-check the rebuild.
That functional check is the single highest-leverage thing in the whole alternative path. It’s the one failure that won’t announce itself later, and unlike the dimension peek, it actually distinguishes a right index from a wrong one.
Diagram for the live demo. If you’re walking someone through this path, the clarifying visual is a before/after of one query against the wrong index: the same question “who is on this page?” producing (a) a tidy ranked list of relevant chunks when query and index share an embedder, vs. (b) a scrambled list of unrelated chunks when they don’t — with the chat answer underneath each, grounded in (a) and hallucinating in (b). It makes “different vector space” concrete in a way the cartographer metaphor only gestures at, and it explains why Step 2 is non-negotiable better than any prose.
The Cost & Latency Ledger
Here’s the trade laid out honestly. Numbers are at portfolio traffic — call it ~100 chat questions per month, bursty, with long idle gaps:
| Modal-hosted Ollama (Posts 14–15) | Anthropic Haiku + Voyage (this post) | |
|---|---|---|
| Chat inference | T4 GPU at ~$0.59/hr × active GPU-minutes + 5-min idle windows | $0.25/M input + $1.25/M output × ~100 q/mo |
| Embeddings | (same Modal endpoint — folded into chat cost) | ~$0.02/M tokens × a few K question-tokens/mo |
| Model weights at rest | ~$1/mo (Modal volume holding qwen2.5:7b + bge-m3) | $0 |
| Monthly chat-layer total | ~$5–10 | ~$0.10 |
| First-answer latency after idle | 15–30 s (allocate GPU + load VRAM) | none from the AI layer; ~5–10 s if Fly itself was asleep |
| Operational pieces | modal deploy, weights volume, proxy-auth tokens | two API keys |
| Self-hosted / data privacy | ✓ prompts never leave your infra | ✗ every prompt → Anthropic, every query → Voyage |
| Matches the series’ local-first thesis | ✓ | ✗ |
| Chat quality out of the box | good, after Post 11’s hardening fights a 7B model | better — Haiku clears the bar with room to spare |
Read the table top-to-bottom and the managed path wins on cost, latency, operational simplicity, and out-of-the-box quality. Read the bottom three rows and the Modal path wins on the things the series is about. That’s the whole decision in one table: if the bottom three rows are why you’re building this, keep the GPU; if the top rows are, skip it.
One honest footnote on the cost column: at this traffic level, both numbers round to “free.” The $5–10 vs. $0.10 gap is real but it’s lunch money. The reason to pick the managed path is rarely the dollars; it’s the latency and the zero operational surface. A recruiter clicking your link gets an answer in a second instead of waiting out a cold start, and you have two fewer things that can break at 2am.
Deploy It: The Three Deltas
The full step-by-step is in docs/deployment-anthropic.md. It reuses Posts 14–15’s Neon, R2, seed-dump, and Pages steps verbatim and only re-explains the AI layer. Against the Posts 14–15 flow, there are exactly three deltas:
Delta 1 — Skip the Modal step entirely. There’s no modal deploy, no weights volume, no proxy tokens. Instead, get two API keys and smoke-test them before trusting them:
1
2
3
4
5
6
7
8
9
10
11
12
13
cp .env.production.anthropic.example .env.production
$EDITOR .env.production # fill in ANTHROPIC_API_KEY, VOYAGE_API_KEY, Neon, R2, CORS
set -a && source .env.production && set +a
# Anthropic — expect a short JSON reply.
curl -sS https://api.anthropic.com/v1/messages \
-H "x-api-key: $ANTHROPIC_API_KEY" -H "anthropic-version: 2023-06-01" \
-H "content-type: application/json" \
-d '{"model":"'"$ANTHROPIC_MODEL"'","max_tokens":16,"messages":[{"role":"user","content":"ping"}]}'
# Voyage — expect a 1024-long embedding back.
curl -sS https://api.voyageai.com/v1/embeddings \
-H "Authorization: Bearer $VOYAGE_API_KEY" -H "content-type: application/json" \
-d '{"input":["ping"],"model":"'"$VOYAGE_MODEL"'"}'
Delta 2 — Re-index Chroma with Voyage before dumping the seed. That’s §4 above: rm -rf data/chroma, re-ingest per episode, ingest_wiki.py, then the functional grounded-query check (a count-and-dimension peek can’t catch this one, since bge-m3 and voyage-4-lite are both 1024-dim). This is the delta that has no Posts 14–15 analog and the one not to skip.
Delta 3 — Flip the providers and push the alternative secrets. Edit fly.toml’s [env] to set CHAT_PROVIDER='anthropic' and EMBEDDING_PROVIDER='voyage' (next section explains why there and not in secrets), then push the API keys:
1
2
3
4
5
6
7
8
9
set -a && source .env.production && set +a && fly secrets set \
ANTHROPIC_API_KEY="$ANTHROPIC_API_KEY" ANTHROPIC_MODEL="$ANTHROPIC_MODEL" \
VOYAGE_API_KEY="$VOYAGE_API_KEY" VOYAGE_MODEL="$VOYAGE_MODEL" \
DATABASE_URL_OVERRIDE="$DATABASE_URL_OVERRIDE" POSTGRES_RESTORE_URL="$POSTGRES_RESTORE_URL" \
R2_ACCOUNT_ID="$R2_ACCOUNT_ID" R2_ACCESS_KEY_ID="$R2_ACCESS_KEY_ID" \
R2_SECRET_ACCESS_KEY="$R2_SECRET_ACCESS_KEY" R2_BUCKET="$R2_BUCKET" \
R2_PUBLIC_URL_PREFIX="$R2_PUBLIC_URL_PREFIX" CORS_ORIGINS="$CORS_ORIGINS"
./infra/dump_seed.sh && fly deploy
Everything else — Neon provisioning, R2 upload, the Pages connect-and-build, the CORS_ORIGINS round-trip — is byte-for-byte Posts 14–15. When you open the *.pages.dev URL and ask a question, the first answer is fast, with no GPU to wake. That speed is the demo for this path, the same way the choreographed cold start was the demo for Posts 14–15’s.
The fly.toml Trap: [env] vs. Secrets
One subtlety the deploy guide flags and that’s worth understanding rather than copy-pasting past. The committed fly.toml carries an [env] block tuned for the default path:
1
2
3
4
5
[env]
CHAT_PROVIDER = 'ollama'
EMBEDDING_PROVIDER = 'ollama'
STORAGE_BACKEND = 'r2'
# ...
So if you only fly secrets set ANTHROPIC_API_KEY=... and leave it there, the backend still reads CHAT_PROVIDER=ollama from [env], tries to reach a Modal URL you never deployed, and fails. You have to override the providers.
There are two ways to do it, and the choice is a small lesson in config hygiene. Fly resolves environment variables from both fly.toml’s [env] block and fly secrets, and when a name appears in both, the secret wins — Fly secrets take precedence over [env] values (Fly config reference; Fly community confirmation). So fly secrets set CHAT_PROVIDER=anthropic would work.
But you shouldn’t. CHAT_PROVIDER and EMBEDDING_PROVIDER aren’t secrets; they’re configuration, and configuration belongs in version-controlled fly.toml where the next person (including future-you) can see it, not buried invisibly in your Fly account’s secret store. The rule of thumb: secrets are for things that would be dangerous to commit; everything else is [env]. API keys go in fly secrets; the provider choice goes in fly.toml:
1
2
3
4
[env]
CHAT_PROVIDER = 'anthropic'
EMBEDDING_PROVIDER = 'voyage'
STORAGE_BACKEND = 'r2'
That the precedence rule lets you do it the sloppy way is exactly why it’s worth naming the clean way explicitly.
What’s Honest, What’s Open
Four things to say plainly, in the spirit of every post in this series.
Your prompts and queries leave your infrastructure. Every chat message is sent to Anthropic; every retrieval query is sent to Voyage. For a public, CC-BY comic companion this is a non-issue — there’s nothing private about asking who’s on a page of a freely-licensed webcomic. But it is the exact property the local-first thesis existed to protect, and it would matter the instant real user data flowed through the same path. If you ever put this in front of authenticated users, the data-processing implications (retention settings, DPAs) become a real consideration, and that’s a different post.
This path abandons the series’ thesis, on purpose. Posts 2 through 15 were a sustained argument that you can serve your own models well and cheaply. This post reaches for someone else’s models because, for some readers, that argument isn’t the one they’re trying to make. There’s no contradiction in shipping both. The workshop’s whole point is that the architecture supports either, and demonstrating the swap is a stronger portfolio signal than committing to one religion. But if a reviewer asks “I thought this was a local-first project,” the honest answer is “it is — and it’s built so it doesn’t have to be, which is the more interesting claim.”
The re-index is a footgun, and the guide treats it as one. Everything else on this path is genuinely config-only, which lulls you into thinking the whole thing is. The vector-space rebuild is the exception, and its silent failure mode is the most likely way a first deploy of this path goes subtly wrong — grounded-looking machinery producing ungrounded answers. The standalone guide makes it Step 2, gives it a verification check, and puts its signature (non-empty retrieved_doc_ids + ungrounded answer) in the troubleshooting table. That’s the right amount of ceremony for the one thing that bites.
The live demo is a metered, public, unauthenticated endpoint, so it’s guarded, but the real ceiling is a spend cap. Unlike the Modal path, where idle cost is near-zero and a busy day mostly buys GPU seconds, every question here makes two paid API calls (the Anthropic answer + the Voyage embedding). The chat route has no auth, and CORS only keeps browsers on the right origin; it does nothing to a script hitting the Fly URL directly. So the workshop adds two app-level guards: a per-IP sliding-window rate limit (20 questions/minute, 429 past that) and a 2,000-character cap on each message that rejects oversized input with a 422 before any model call, closing the one unbounded cost vector, since the output is already token-capped. But both are defense-in-depth. The actual dollar ceiling is the spend limit you set in the Anthropic console, because an in-process limiter can’t stop a botnet spread across many IPs and resets every time the machine scales to zero. For a portfolio demo that’s the right amount of armor: organic traffic and a casual script both cost cents, and a hard spend cap bounds the worst case to “the demo stops answering until next month” rather than a surprise invoice. Naming where the real guard sits, provider-side rather than app-side, is itself part of the honesty.
What I didn’t do: deploy this exact tagged path to live Anthropic and Voyage accounts before writing. What I verified is that the VoyageEmbeddingClient and AnthropicChatClient pass their unit tests, that the factory dispatches on the two env vars, and that re-indexing under EMBEDDING_PROVIDER=voyage rebuilds data/chroma against voyage-4-lite and answers a grounded probe query locally. The deploy mechanics are Posts 14–15’s, which were derived from a real deploy of the same architecture. Treat the smoke-tests in the guide as the experiment that turns high confidence into confirmation before you put the URL in front of anyone.
Key Takeaways
1. A good abstraction is one you can swap across without opening the file on the other side. The orchestrator, retrieval, and prompts were written against the Post 4 Protocols, not against Ollama. Swapping the entire AI layer to two hosted APIs touched zero lines of that code; it added factory branches and flipped two env vars. The portfolio claim isn’t “I integrated Anthropic”; it’s “the seams I drew two months ago made integrating Anthropic a no-op everywhere except the seam itself.”
2. “Skip the model host” never means “skip embeddings.” Retrieval embeds every question on every request, independent of which model writes the answer. The most common conceptual error on this path is assuming a powerful chat API absorbs the search step. It doesn’t — search is a separate problem with its own model, and you have to give it a home.
3. Embeddings from different models live in different, incompatible spaces. This is the load-bearing fact of the whole alternative path. You cannot point a Voyage query at a bge-m3 index and get meaningful rankings, and the failure is silent: fluent answers grounded in noise. Any time you change embedding models, you re-index, and you verify the dimensionality to prove the change took.
4. Put secrets in secrets and config in config — even when the platform lets you cheat. Fly secrets override fly.toml [env], so you can set CHAT_PROVIDER as a secret. Don’t. The provider choice is configuration that belongs in the repo; only the API keys are dangerous-to-commit. The precedence rule existing is not a license to misuse it.
5. The cheapest, fastest, simplest path is sometimes the one that’s off-thesis, and naming that trade is the skill. Managed APIs beat the self-hosted GPU on cost, latency, and ops. They lose on privacy and on the story the series is telling. Neither table half is “right.” The judgment a portfolio is meant to show isn’t which you pick; it’s that you can see both columns clearly and choose deliberately.
Which Path Should You Ship?
If you’ve read this far you have both paths in hand and a fork to resolve. Here’s the decision compressed to a sentence each:
Ship the Modal path (Posts 14–15) if your portfolio story is “I can serve open models myself, privately, on commodity hardware, cheaply.” That’s a strong, increasingly relevant story, and the 15-second cold start is a footnote you can choreograph around.
Ship the managed-API path (this post) if your portfolio story is “I built a product with clean seams, and I make the build-vs-buy call deliberately per component.” The instant first answer and the rounding-error bill are real advantages, and the Post 4 abstraction is what lets you make the call at all.
Ship neither as a religion. The most honest version of this project keeps both documented and says, in the README, “here’s how to deploy it either way, and here’s the trade.” That sentence, “I designed it so this is a config flip, and here’s when I’d flip it,” is the thing a reviewer who has shipped real systems actually wants to hear. The architecture earns it; the two deploy guides prove it.
The series set out to build a warm, spoiler-safe reading companion for a webcomic and, along the way, to argue that the boring engineering discipline — decide what to abstract, abstract exactly that, leave the rest alone — is what makes the interesting choices cheap later. Posts 14–15 cashed that discipline to move off localhost. Post 16 cashes it again to move off the GPU. Same seam, second payout. That’s the whole point of having drawn it.
Try the result live at pepper-carrot-ai-flipbook.devcloudweb.com — the Anthropic + Voyage deploy this post walks through. Code for this post — the env template, the standalone guide, and the ADR — is in the workshop starter at the post-16-managed tag. The runtime clients it documents (AnthropicChatClient, VoyageEmbeddingClient) ship behaviorally unchanged from earlier tags — the only code delta is bumping the default chat + embedding models to claude-haiku-4-5 and voyage-4-lite — which was the point.