Pepper & Carrot AI-powered flipbook · Part 8 — A React Flipbook in the Browser: StPageFlip and a Page-Turn UI
Post 8 of the Pepper & Carrot AI flipbook series. Post 7 built two typed REST routes that return episode JSON with absolute image URLs; this post renders that data as a real page-flipping flipbook in the browser. A Vite + React + TypeScript frontend, a hand-rolled types.ts that mirrors the Pydantic models, an episode picker, and a
Post 8 of the Pepper & Carrot AI-powered flipbook series. Post 7 built the backend half: two typed FastAPI routes, GET /api/episodes and GET /api/episodes/{slug}, that return episode JSON with pages.image_url relative keys already resolved into absolute URLs at response time, with the OpenAPI spec as the written-down wire-format contract. All of it curl-able, none of it visible in a browser. This post crosses the wire. We hand-write a TypeScript mirror of the Pydantic response models, build a tiny fetch client and an episode picker, and wrap StPageFlip in a React component so a reader can flip through a real page-turning book — single page in portrait, a two-page spread in landscape. By the end, a reader can pick an episode and flip through it like a real book, and three appendices go deeper on the two SQLAlchemy idioms behind the Post 7 handlers and on how Settings reads your .env.
What you’ll build in this post.
- A
frontend/directory at the repo root: Vite + React + TypeScript scaffold, a small typedfetchwrapper, a hand-rolledtypes.tsthat mirrors the Pydantic models from Post 7, a minimal episode-picker, and a real flipbook reader.- A
<Flipbook>component wrapping StPageFlip — single page in portrait, two-page spread in landscape, switching live as the viewport changes.- The picker ↔ reader view-switch in
App.tsxas a singleuseState, withselectedEpisode,currentPage, andorientationlifted to where later posts’ chat panel can read them.- The dev-server proxy + production CORS story that lets the frontend talk to the backend across origins.
Prerequisites.
- Post 7 done: the two REST routes from
backend/app/api/episodes.pyreturning episode JSON with absolute image URLs. Confirm withcurl -s http://localhost:8000/api/episodes | jq '.episodes | length'.- The workshop starter at the state Post 5 left it in: Postgres up,
alembic upgrade headapplied,seed.pyrun, and Episode 1 ingested by theingest-from-imagesskill.- Node.js 20+ installed (we set this up in Post 2 step 1). Confirm with
node --version.- No new external services. Everything in this post runs against the same local stack you already have.
About the repo URL. The entire
frontend/directory — and the backend additions Post 7 covered — live in the same workshop starter that backed Posts 2–5. Pull the latest to pick up the full-stack additions. The full project repository — chat orchestrator, world-graph overlay, cloud deploy — still goes up alongside the deploy guide near the end of the series.Checking out the code. This post shares one checkpoint with Post 7 (the typed REST API):
git checkout post-07-08-fullstackgives you both the backend routes and the React reader in this post. Each later post adds its own tag (post-09-rag,post-10-streaming, …); see the README’s Following along with the blog series.
Table of Contents
- The Frontend’s Type Contract: Hand-Rolled, For Now
- The Frontend Stack in Three Lines
- The Flipbook Component: Wrapping StPageFlip Cleanly
- Single Page vs Two-Page Spread
- The Episode Picker and the View Switch
- The Request, End to End
- Running It on Your Laptop
- Key Takeaways
- Appendix: Going Deeper
The Frontend’s Type Contract: Hand-Rolled, For Now
Now we cross the wire. The frontend’s job is to call those two URLs, parse the JSON, and render it. There are two real choices about how to keep its types in sync with the backend:
Option A: Generate the types. Run openapi-typescript over the FastAPI /openapi.json and let it emit a schema.d.ts file the frontend imports from. The backend renames episode_number to number, the next npm run gen:api regenerates, the frontend’s TypeScript compilation breaks loudly. Drift becomes a compile error.
Option B: Hand-write the types. A frontend/src/api/types.ts file with TypeScript interfaces that mirror the Pydantic models. The backend renames a field, and somebody has to remember to edit types.ts to match. Drift can sneak in.
Option A is what you want at any non-trivial API size. The drift problem is real, the cost of the generator is one CLI invocation, and the resulting types are exact reflections of the spec.
This post chooses Option B anyway, and the reason is calibration. At two endpoints, the entire types.ts is ~30 lines:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// frontend/src/api/types.ts
export interface ImageMetadata {
width?: number;
height?: number;
blurhash?: string;
dominant_color?: string;
}
export interface Character {
id: string;
name: string;
image_url?: string | null;
}
export interface Page {
id: string;
page_number: number;
image_url: string;
thumbnail_url: string | null;
image_metadata: ImageMetadata;
characters: Character[];
}
export interface Episode {
id: string;
slug: string;
title: string;
episode_number: number;
cover_image_url: string | null;
page_count: number;
plot_summary: string | null;
}
export interface EpisodeDetail extends Episode {
credits_url: string | null;
characters: Character[];
pages: Page[];
}
You can read this whole file at a glance and see whether it matches the Pydantic models on the other side. Adding a generator at this scale would mean adding a dev dependency, a build step, a generated file in version control with merge-conflict noise, and a npm run gen:api ritual that doesn’t earn its keep until the API surface is large enough that humans actually miss drift. The hand-rolled version is honest about what’s happening: both sides own the contract, and both sides need to read it when they edit. Once the API hits ~6 endpoints or starts adding nested response shapes (think enum fields, discriminated unions, paginated wrappers), graduate to a generator. The seam is one import type { ... } line in the API client, and that’s the place that doesn’t change.
The actual API client is a tiny fetch wrapper:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// frontend/src/api/client.ts
import type { Episode, EpisodeDetail } from './types';
const BASE_URL = import.meta.env.VITE_API_BASE_URL ?? '';
async function get<T>(path: string): Promise<T> {
const res = await fetch(`${BASE_URL}${path}`);
if (!res.ok) {
throw new Error(`GET ${path} failed: ${res.status}`);
}
return res.json() as Promise<T>;
}
export const api = {
listEpisodes: () => get<{ episodes: Episode[] }>('/api/episodes'),
getEpisode: (slug: string) => get<EpisodeDetail>(`/api/episodes/${slug}`),
};
VITE_API_BASE_URL is read from frontend/.env (or empty string in dev, when Vite’s proxy intercepts /api). At two endpoints the indirection of a query library or a typed-fetch wrapper costs more than it pays, but the Promise<T> return types here are the seam any future migration to openapi-fetch or TanStack Query would slot into. Build the seam; defer the library.
The Frontend Stack in Three Lines
The full frontend stack for this post is three primary tools — chosen because they are the minimum that gives a credible reading experience without ceremony.
| Tool | What it does | Why this one |
|---|---|---|
| Vite | Dev server + production bundler for the React app. | Near-instant cold start, native ESM, and a single vite.config.ts. The previous default in this space (Create React App) is deprecated; Vite is what the React team now points at. |
| React + TypeScript | UI library + type system. | The UI surface is small enough that any framework would work. React + TypeScript is the default in the industry; using anything else here trades signal for novelty. |
| page-flip (StPageFlip) | A real page-flipping flipbook: corner peel, physics, the works. | The whole point of this UI is that pages flip like a real book. Re-implementing that is a deep rabbit hole; the StPageFlip library is well-maintained, framework-agnostic, ~30 KB minified, and has the right primitives (orientation switching, page-flip events) baked in. |
That’s it. No router, no query library, no CSS framework, no state-management library. The picker ↔ reader switch is one useState. Data fetching is useEffect + fetch. CSS is a hand-written stylesheet using CSS variables for the palette. Anything else gets added when something concrete demands it: react-router-dom lands when deep-linking to a page becomes a real feature, a query library lands when caching or focus-refetch starts mattering, an animation library lands when there’s animation to write.
Scaffold the project:
1
2
3
4
cd path/to/pepper-carrot-companion-workshop
npm create vite@latest frontend -- --template react-ts
cd frontend
npm install page-flip
The Vite config gets one tweak: a dev-server proxy so /api/* and /images/* calls go to FastAPI in development. (In production they go to the same origin via CORS, so the proxy is dev-only.)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// frontend/vite.config.ts
import { defineConfig } from 'vite';
import react from '@vitejs/plugin-react';
export default defineConfig({
plugins: [react()],
server: {
port: 5173,
proxy: {
'/api': 'http://localhost:8000',
'/images': 'http://localhost:8000',
},
},
});
Why a proxy if we already have CORS? The § Cross-origin requests subsection in Post 7 covered the conceptual side:
http://localhost:5173andhttp://localhost:8000are different origins, andbackend/app/main.pyalready configures the CORS middleware to allow the dev origin. The proxy is the second mechanism. It routes/api/*and/images/*through Vite at:5173, which makes those fetches look same-origin to the browser and skips the CORS check entirely. The pay-off is a cleaner DevTools network tab in dev. CORS still earns its keep in production, where the dev proxy isn’t running and the frontend (Cloudflare Pages) lives on a different origin than the backend (Fly).
The entry point is a four-line main.tsx:
1
2
3
4
5
6
7
8
9
10
11
// frontend/src/main.tsx
import React from 'react';
import ReactDOM from 'react-dom/client';
import { App } from './App';
import './styles/global.css';
ReactDOM.createRoot(document.getElementById('root')!).render(
<React.StrictMode>
<App />
</React.StrictMode>
);
Everything else is App.tsx and two components — we’ll get to all three below.
The Flipbook Component: Wrapping StPageFlip Cleanly
StPageFlip is a vanilla-JS library that takes a container element and a list of page elements and gives you a real, physics-y page-flipping flipbook, where clicking the corner of a page peels it like a paperback. There’s no official React wrapper, and the imperative API is a square peg for React’s render-time-only model. Wrapping it correctly is the bulk of this section.
The pattern that works: let React own a wrapper <div>, give StPageFlip an inner element React doesn’t render, and destroy/recreate the inner element across episodes. This keeps the two ownership models, declarative for the surrounding chrome and imperative for the library’s DOM subtree, from stepping on each other.
The full component, abridged for the page-flow but preserving every load-bearing bit:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
// frontend/src/components/Flipbook.tsx
import { useEffect, useRef, useState } from 'react';
import { PageFlip } from 'page-flip';
import { api } from '../api/client';
import type { Episode, EpisodeDetail } from '../api/types';
interface FlipbookProps {
episode: Episode;
onPageChange: (pageNumber: number) => void;
// Fires on init and whenever PageFlip switches between portrait (single page)
// and landscape (two-page spread). Lets the parent phrase the page indicator
// correctly ("Pages N–N+1" when both are visible).
onOrientationChange?: (mode: 'portrait' | 'landscape') => void;
}
export function Flipbook({ episode, onPageChange, onOrientationChange }: FlipbookProps) {
const containerRef = useRef<HTMLDivElement>(null);
const flipRef = useRef<PageFlip | null>(null);
const onPageChangeRef = useRef(onPageChange);
const onOrientationChangeRef = useRef(onOrientationChange);
const [detail, setDetail] = useState<EpisodeDetail | null>(null);
const [error, setError] = useState<string | null>(null);
const [currentPage, setCurrentPage] = useState(1);
// Keep the latest callback in a ref so the PageFlip effect doesn't
// re-run on identity changes — only when the episode itself changes.
useEffect(() => { onPageChangeRef.current = onPageChange; }, [onPageChange]);
useEffect(() => {
onOrientationChangeRef.current = onOrientationChange;
}, [onOrientationChange]);
// Fetch the episode detail when the slug changes.
useEffect(() => {
setDetail(null);
setError(null);
setCurrentPage(1);
api.getEpisode(episode.slug).then(setDetail).catch((err) => setError(String(err)));
}, [episode.slug]);
// Build the flipbook once the detail is loaded.
useEffect(() => {
if (!detail || !containerRef.current) return;
const wrapper = containerRef.current;
// Wipe any stale flipbook DOM React doesn't own. React StrictMode's
// dev-only setup → cleanup → setup cycle can leave the first PageFlip's
// root behind if its destroy chain doesn't fully unmount; the second
// flipbook then renders over it and you see duplicate pages mid-flip.
while (wrapper.firstChild) wrapper.removeChild(wrapper.firstChild);
// PageFlip takes over the element it's given (and removes it on destroy()),
// so give it an INNER element React doesn't own.
const flipRoot = document.createElement('div');
flipRoot.className = 'flipbook';
wrapper.appendChild(flipRoot);
const pageEls: HTMLElement[] = detail.pages.map((page) => {
const el = document.createElement('div');
el.className = 'page';
el.dataset.pageNumber = String(page.page_number);
const img = document.createElement('img');
img.src = page.image_url;
img.alt = `Page ${page.page_number}`;
img.draggable = false;
el.appendChild(img);
flipRoot.appendChild(el);
return el;
});
const flip = new PageFlip(flipRoot, {
width: 600, height: 847, // matches 2481×3503 source aspect (~1.412)
size: 'stretch', minWidth: 280, maxWidth: 1200,
minHeight: 395, maxHeight: 1700,
maxShadowOpacity: 0.5,
showCover: false,
useMouseEvents: true,
drawShadow: true,
usePortrait: true,
mobileScrollSupport: true,
flippingTime: 700,
});
flip.loadFromHTML(pageEls);
// Single source of truth: read PageFlip's `getCurrentPageIndex()` directly
// on every event. The `flip` event's `e.data` is the page index PageFlip
// just stored internally, which can briefly diverge from what's drawn —
// most reliably on the single-page spread an odd-page-count episode
// produces in landscape (page 3 alone in a 3-page episode), and on
// landscape↔portrait transitions that rebuild the spread layout.
const reportPage = () => {
const pageNumber = flip.getCurrentPageIndex() + 1;
setCurrentPage(pageNumber);
onPageChangeRef.current(pageNumber);
};
flip.on('flip', reportPage);
flip.on('init', reportPage); // captures initial spread
flip.on('changeOrientation', (e) => {
const mode = (e as { data: 'portrait' | 'landscape' }).data;
onOrientationChangeRef.current?.(mode);
reportPage(); // re-sync after spread rebuild
});
// Emit initial orientation immediately so the parent's pill label is
// correct before any user gesture (PageFlip's own `init` event fires
// on the next tick, which is too late for the first render).
onOrientationChangeRef.current?.(flip.getOrientation());
flipRef.current = flip;
return () => {
flip.destroy(); // removes flipRoot from wrapper; React's wrapper stays.
flipRef.current = null;
};
}, [detail]);
// Preload current ± 2 pages so the next flip has the image ready.
useEffect(() => {
if (!detail) return;
const targets = detail.pages.filter(
(p) => Math.abs(p.page_number - currentPage) <= 2 && p.page_number !== currentPage
);
const links = targets.map((page) => {
const link = document.createElement('link');
link.rel = 'preload';
link.as = 'image';
link.href = page.image_url;
document.head.appendChild(link);
return link;
});
return () => { links.forEach((l) => l.remove()); };
}, [detail, currentPage]);
if (error) return <div className="error">Failed to load episode: {error}</div>;
if (!detail) return <div className="loading">Loading episode…</div>;
return <div ref={containerRef} className="flipbook-wrapper" />;
}
A few details earn their lines:
- The wrapper / inner split. React renders
<div className="flipbook-wrapper" ref={containerRef} />and stops. The firstuseEffectafter the detail loads appends a second<div className="flipbook">inside, and hands that one tonew PageFlip(...). The cleanup function callsflip.destroy(), which removes the inner div but leaves React’s wrapper untouched. When the parent unmounts the component, React removes the wrapper as usual. Two ownership models, two scopes, no stepped-on toes. - The defensive wrapper wipe (
while (wrapper.firstChild) wrapper.removeChild(...)). Belt-and-suspenders for the wrapper/inner split. React StrictMode’s dev-only setup → cleanup → setup cycle is supposed to leave the wrapper empty between iterations becauseflip.destroy()removes the flipRoot — but if any part of PageFlip’s destroy chain throws or races with a pending initsetTimeout, the stale flipbook stays in the DOM and the next iteration’s flipbook renders on top of it. Visually you’d see ghost pages stacked vertically during a flip animation, or the active spread appearing to “move up” because there’s a leftover spread underneath. One short while-loop wipes any leftover children before we appendChild the fresh root, which costs nothing and rules the failure mode out structurally. - Callbacks live in refs, not in the effect’s dep array.
onPageChangeRefandonOrientationChangeRefare updated by tiny effects of their own. The big “build the flipbook” effect doesn’t depend on them — only on[detail]— so it doesn’t rebuild every time the parent passes a new lambda. (A common bug in this kind of wrapper is depending on the callback identity in the heavy effect; cue a full rebuild on every parent re-render.) flip.destroy()in the cleanup is non-negotiable. Without it, navigating away from the reader and back leaks event listeners and DOM nodes. In React strict mode (which the project uses) you’d see it immediately as a double-instance; without strict mode you’d see it as gradual performance degradation in production.onPageChangereports a 1-indexed page number, read from PageFlip’s own state. Three event handlers (flip,init, andchangeOrientation) share areportPage()helper that doesflip.getCurrentPageIndex() + 1and dispatches the result. We deliberately do not trust thee.datapayload of theflipevent. That value is the page index PageFlip just stored internally, which can briefly diverge from what’s actually drawn on screen — most reliably on the single-page spread that an odd-page-count episode produces in landscape (e.g. page 3 alone in a 3-page episode), and across landscape↔portrait transitions that rebuild the spread layout. Reading the library’s current state inside each handler sidesteps the drift. (We learned this the hard way: the page-indicator pill briefly read “Page 3 of 3” while the spread visibly showed pages 1 and 2, until we switched to thegetCurrentPageIndex()approach.) Post 9’s chat layer will subscribe to exactly this callback to learn what the reader is looking at, so the value being correct matters here, not just in the header.- The
data-page-numberattribute powers a pure-CSS page badge. Each.pageelement getsel.dataset.pageNumber = String(page.page_number); the stylesheet renders that value as a small parchment pill at the bottom-right viacontent: attr(data-page-number)on the::afterpseudo-element. No JavaScript needed to render the per-page indicator; the data flows from JSON → DOM attribute → CSS. - Preload of current ± 2 pages. Browsers don’t preload images that aren’t in the visible DOM yet. A
<link rel="preload">injected into<head>for the next two and previous two pages keeps the next flip’s image ready when the reader gets there. Five<link>tags is cheap; a stuttering flip animation looks bad.
The CSS for the badge, the flipbook frame, and the soft shadow lives in frontend/src/styles/global.css. It’s about 50 lines of styling and not interesting on its own; see the source link at the end of the post.
Single Page vs Two-Page Spread
The flipbook component above already handles this: flip.on('changeOrientation', ...) fires whenever StPageFlip switches between portrait (single page) and landscape (two-page spread) based on viewport dimensions, and the component forwards the new mode through onOrientationChange and re-emits the visible page via reportPage() (so the page-indicator pill stays accurate when the spread layout rebuilds). But the why is worth a section, because portrait/landscape rendering is a constant source of buggy comic readers and StPageFlip gives us the right primitive almost for free.
The behavior we want:
- Landscape viewport (wide screen, the common laptop case): two-page spread. Pages 2-3 face each other, then 4-5, then 6-7. Same way a real book opens.
- Portrait viewport (phone, tablet, narrow window): one page at a time. Pages flip individually, no facing pair.
StPageFlip handles the switch internally based on the container’s aspect ratio at the moment it computes the layout — initial mount, resize, or explicit update(...) call. The changeOrientation event we subscribe to is how we learn about the switch from outside; the library has already done the work of reshaping the layout by the time the event fires.
The parent (App.tsx) uses this to phrase the page-indicator pill correctly. When orientation is 'landscape' and the right page exists (i.e., we’re not on the final odd page), the pill reads “Pages 4–5 of 9”; otherwise “Page 4 of 9”. Two-line snippet:
1
2
3
4
const showSpread = orientation === 'landscape' && rightPage > currentPage;
const pageLabel = showSpread
? `Pages ${currentPage}–${rightPage} of ${totalPages}`
: `Page ${currentPage} of ${totalPages}`;
Plain-English aside: what does “spread” mean here? A spread is the pair of two pages a reader sees side-by-side when a real book is open — the verso (left) and recto (right). Most comics are drawn page-by-page, but plenty of pages are spread-aware: page 4 and page 5 of Pepper & Carrot episode 6, for example, are a single watercolor scene that crosses the gutter. Rendering them as one spread on a landscape screen recovers the artist’s intent in a way single-page reading can’t.
The Episode Picker and the View Switch
Two pieces remain: a picker that lists episodes and the top-level App.tsx that switches between the picker and the reader.
The picker
A grid of episode cards. Each card is a real click target (the whole card opens the episode), with a small “Read more” toggle inside the summary for plot summaries that exceed three lines. The picker component is the file new readers tend to land on first, so it’s worth showing in full:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
// frontend/src/components/EpisodePicker.tsx (abridged)
import { useEffect, useState } from 'react';
import { api } from '../api/client';
import type { Episode } from '../api/types';
export function EpisodePicker({ onSelect }: { onSelect: (e: Episode) => void }) {
const [episodes, setEpisodes] = useState<Episode[] | null>(null);
const [error, setError] = useState<string | null>(null);
useEffect(() => {
api.listEpisodes().then((r) => setEpisodes(r.episodes)).catch((e) => setError(String(e)));
}, []);
if (error) return <div className="error">Failed to load episodes: {error}</div>;
if (!episodes) return <div className="loading">Loading episodes…</div>;
return (
<div className="episode-picker">
<header className="picker-hero">
<div className="picker-hero__inner">
<p className="picker-hero__eyebrow">A reading companion for</p>
<h1 className="picker-hero__title">Pepper&Carrot</h1>
<p className="picker-hero__subtitle">
Step into the world of Hereva alongside a young Chaosah witch and her impulsive cat.
Pick an episode below to start reading.
</p>
</div>
</header>
<ul className="episode-grid">
{episodes.map((ep) => (
<li key={ep.id}>
<EpisodeCard episode={ep} onOpen={() => onSelect(ep)} />
</li>
))}
</ul>
</div>
);
}
The pattern worth pulling out is the fetch + useState data path. Three lines: a useEffect fires the request on mount, success calls setEpisodes, failure calls setError. The JSX branches on error and episodes === null to render three states (error / loading / loaded) declaratively. No library involved. This is the part that, in a larger app, would get caching, dedup, and focus-refetch via TanStack Query or SWR, and it’s worth knowing when to graduate. Three signals: (1) the same data is being refetched in multiple components, (2) loading states are flickering on quick re-mounts, (3) you start writing your own cache. None of those bite at one screen.
The inner EpisodeCard (not shown — see the source) renders the cover image, a “Episode N” badge in the corner, the title, the plot summary with the optional “Read more” toggle, and a footer with the page count plus a “Read →” CTA. The whole card has role="button" plus a keyboard handler so it’s accessible to keyboard users without nested-interactive-element warnings — the inner toggle uses stopPropagation so clicking it doesn’t also open the episode.
The view switch
Without a router, App.tsx does the picker ↔ reader switch with a single piece of state:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
// frontend/src/App.tsx
import { useState } from 'react';
import { EpisodePicker } from './components/EpisodePicker';
import { Flipbook } from './components/Flipbook';
import type { Episode } from './api/types';
export function App() {
const [selectedEpisode, setSelectedEpisode] = useState<Episode | null>(null);
const [currentPage, setCurrentPage] = useState<number>(1);
const [orientation, setOrientation] = useState<'portrait' | 'landscape'>('landscape');
if (!selectedEpisode) {
return <EpisodePicker onSelect={setSelectedEpisode} />;
}
const totalPages = selectedEpisode.page_count;
const rightPage = Math.min(currentPage + 1, totalPages);
const showSpread = orientation === 'landscape' && rightPage > currentPage;
const pageLabel = showSpread
? `Pages ${currentPage}–${rightPage} of ${totalPages}`
: `Page ${currentPage} of ${totalPages}`;
return (
<div className="app-layout">
<header className="app-header">
<button className="header-back" onClick={() => setSelectedEpisode(null)}>
← Episodes
</button>
<h1>{selectedEpisode.title}</h1>
<span className="header-page-indicator" aria-live="polite">{pageLabel}</span>
</header>
<main className="app-main">
<Flipbook
episode={selectedEpisode}
onPageChange={setCurrentPage}
onOrientationChange={setOrientation}
/>
</main>
</div>
);
}
Three pieces of state lifted up here — selectedEpisode, currentPage, orientation — are the seams Post 9 (chat) and later posts (world graph) will plug into. The chat panel needs selectedEpisode.slug to scope its retrieval, currentPage to scope spoiler filtering, and orientation to phrase its context hint (“Reading pages 4–5”). All three are already here, lifted to where any sibling component can read them.
What’s not here: no react-router-dom, no URL synced to the selected episode, no deep-link to a specific page. Those are worth adding, and Post 9 will add them when the chat panel needs durable page state across reloads. But they’re not what this post is about, and adding them now would muddle the picker/reader narrative.
The Request, End to End
Here’s everything we just built, in one picture. A reader clicks an episode in the picker, the browser asks for that episode’s pages, the FastAPI handler joins Postgres with the Storage Protocol’s URL composition, and the JSON comes back with absolute URLs the <img> tags can drop straight into src.
The full request flow. The browser issues one JSON request and gets back absolute image URLs; the <img> tags then fetch the bytes directly from FastAPI’s static-files mount (or, in production, from R2 with the same key shape). The Storage Protocol is the only place URLs are composed — flipping STORAGE_BACKEND=r2 in .env rewires the same key shape to a different URL prefix with zero migration. Click the diagram to open it full-size in a new tab.
The architectural property to notice is that there is no shared state between the two halves except the JSON contract. The frontend has no idea what database is on the other end of the API; the backend has no idea what frontend framework is consuming the spec. Either side can be replaced — swap React for SolidJS, swap FastAPI for Litestar — with the other untouched. The OpenAPI spec is what makes this true in practice rather than just in slogan.
Running It on Your Laptop
The § Tour + Quick Start at the top of Post 7 covered the three commands you need to see the app render: Postgres up, backend on :8000, frontend on :5173. This section is the verification recipe that complements it: the proofs that the seams in the post actually hold, plus the GIF of the end result so you know what to expect.
What it looks like running
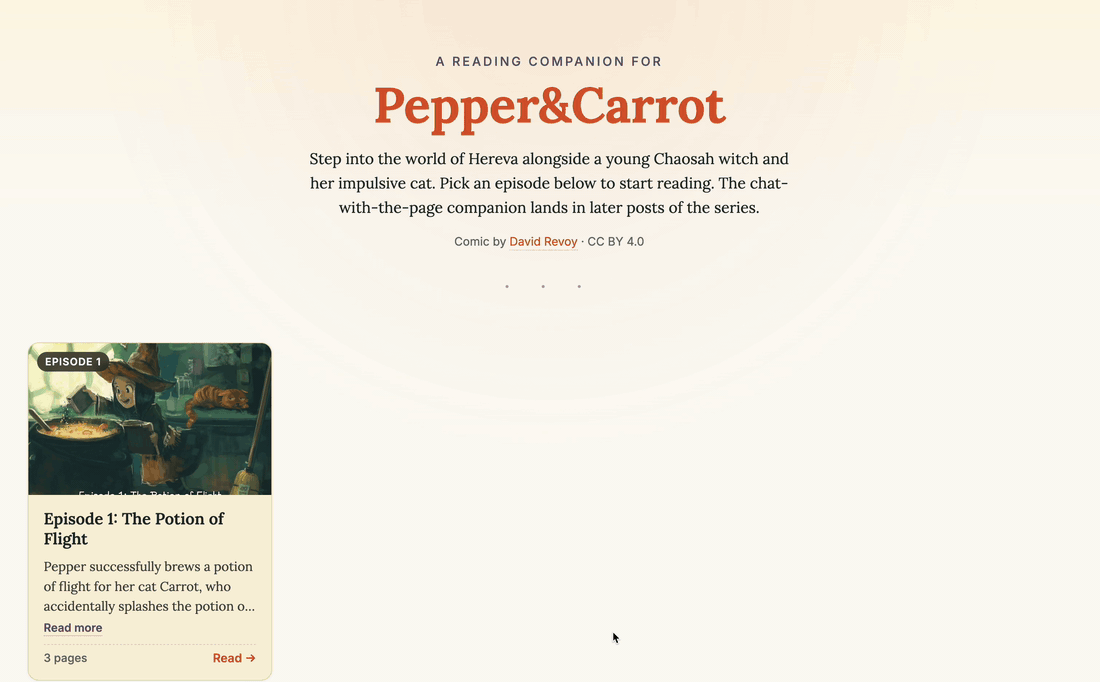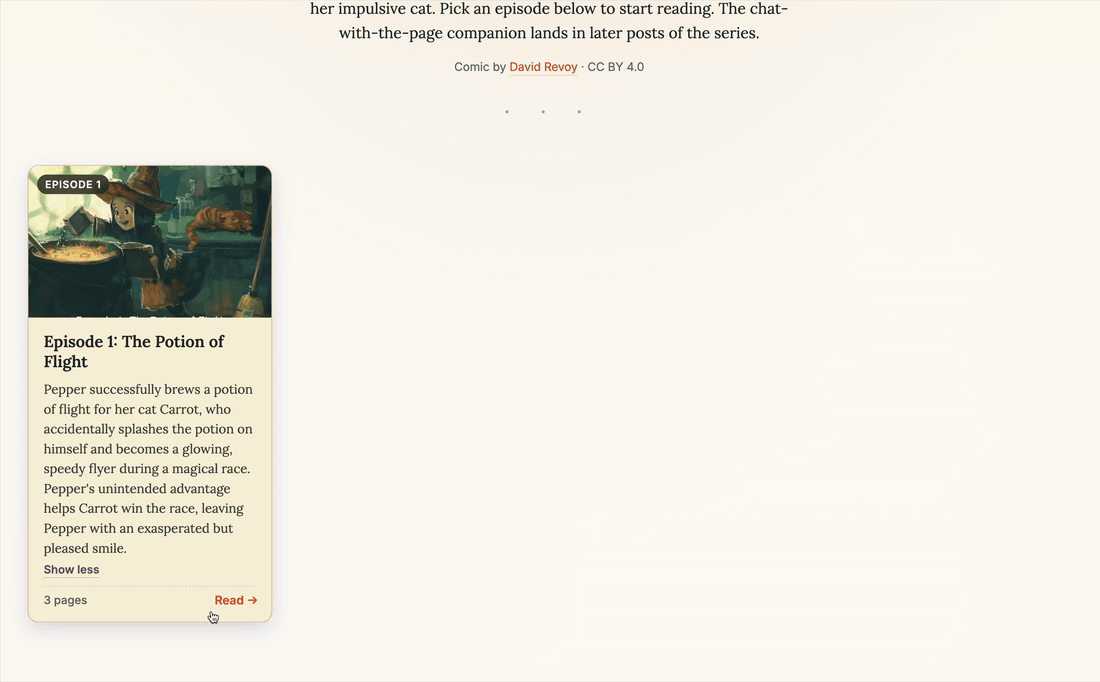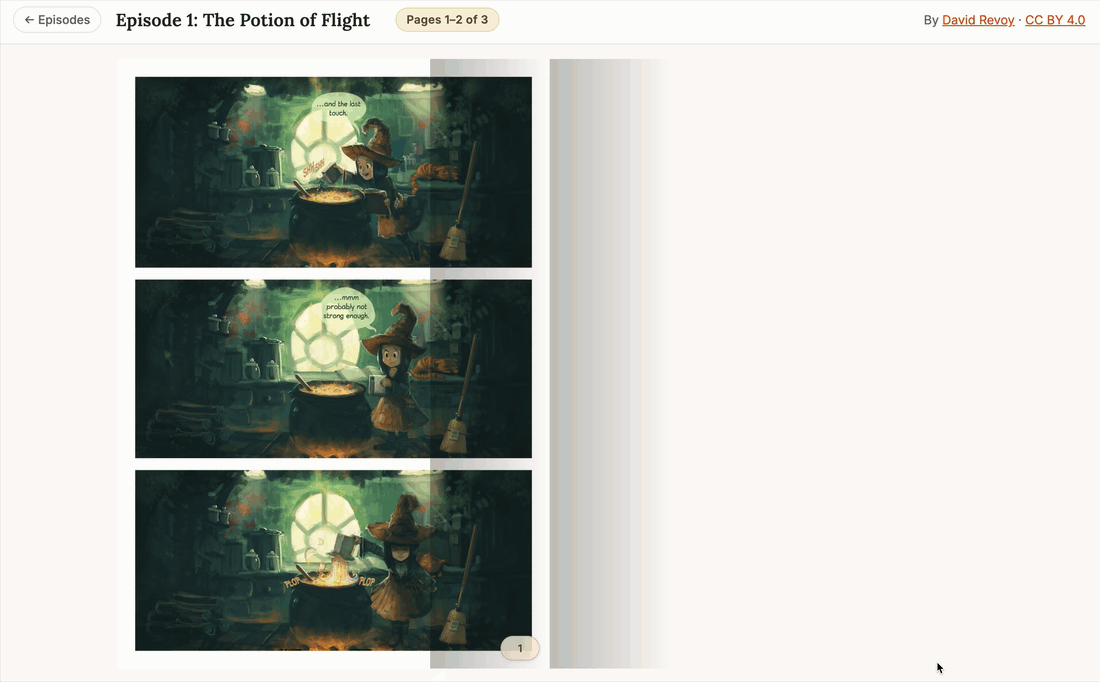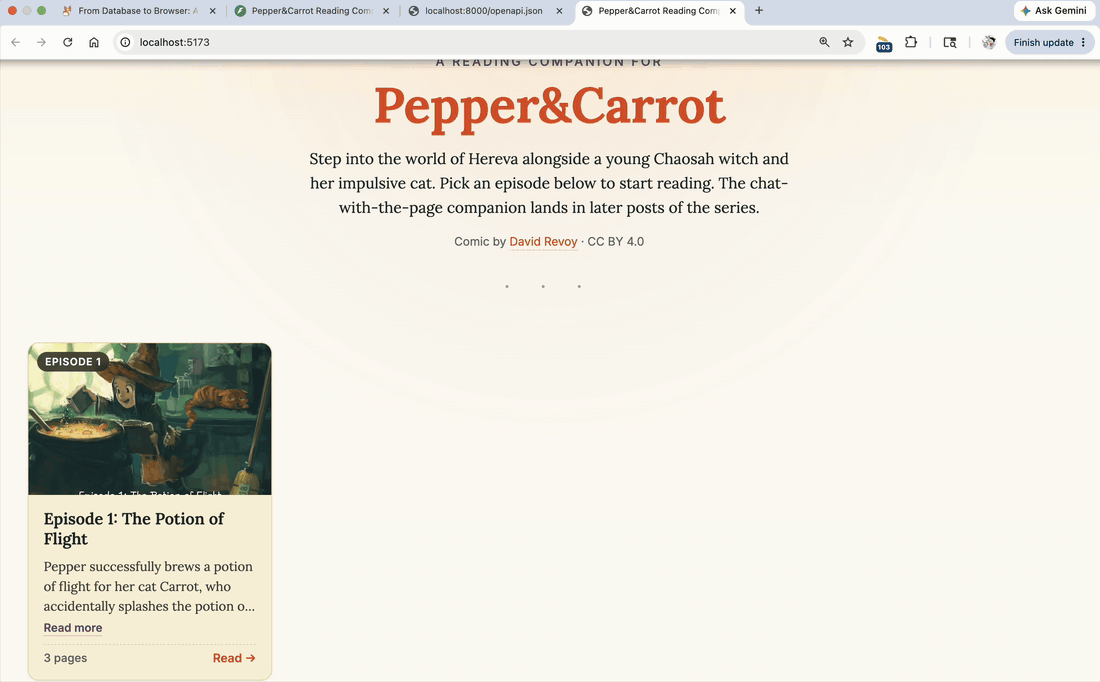 The episode picker plus the flipbook reader, end to end. Three pages of episode 1 rendering from the local backend through
The episode picker plus the flipbook reader, end to end. Three pages of episode 1 rendering from the local backend through LocalStorage.url_for() and <img> tags. Resize the window to portrait and the flipbook collapses to single-page mode; back to landscape and it rebuilds the spread. (Click to enlarge.)
The smoke tests prove the seam
Three hermetic pytest cases in backend/tests/test_episodes_api.py cover the URL-composition seam without needing Postgres ingested. They inject a fake DB session and a stubbed Storage via FastAPI’s dependency_overrides, then assert:
GET /api/episodesreturns the episode with the cover URL resolved throughstorage.url_for().GET /api/episodes/{slug}returns every page withimage_urlandthumbnail_urlstarting with the resolved prefix — proving the relative-key → absolute-URL substitution happened.GET /api/episodes/does-not-existreturns404.
1
2
cd backend && uv run pytest -v tests/test_episodes_api.py
# 3 passed
Test what’s load-bearing — the relative key turning into an absolute URL at response time — and skip what isn’t. The flipbook’s render path is much faster to verify with eyes on a browser than with a JSDOM test, so don’t write one.
Type-check + build the frontend
1
2
3
cd frontend
npm run type-check # tsc -b --noEmit, no output = pass
npm run build # Vite production build
If the backend ever renames a Pydantic field in a way that drifts from frontend/src/api/types.ts, this is the place you’ll catch it: either a TypeScript compile error during type-check, or a runtime undefined when a component reads the renamed-away field. The hand-rolled contract earns its keep when you run these two commands after every API change. (When that becomes annoying, see § The Frontend’s Type Contract for when to graduate to openapi-typescript.)
One more sanity check: the bookmarkable URL isn’t here yet
Try copy-pasting the reader URL and you’ll notice it stays http://localhost:5173/ even after you click into Episode 1, because we haven’t wired up react-router-dom. That’s a feature gap, not a bug, and it’s the right call for this post: nothing yet uses a deep link. Post 9 introduces the chat session, which is where a URL-synced page index becomes necessary, and that’s when a router earns its place. Until then, the picker → reader switch is one useState and that’s enough.
Key Takeaways
1. Design the API surface backwards from screens, not forward from tables. Two screens, two endpoints. Designing forward from the episodes and pages tables would have given you three or four “RESTful” endpoints that match nothing the UI actually loads. Backwards-from-screens produces fatter, fewer responses that match how the frontend renders, which is what minimizes round-trips and removes the “do I need to make another call?” loop from every component.
2. Make the wire format an artifact, not folklore. FastAPI’s OpenAPI spec is the contract; the Pydantic response models are the source of truth that produces it; the frontend’s types.ts mirrors the same shapes. At two endpoints, mirroring by hand is honest and legible: both sides own the contract and both sides can read it. Graduate to openapi-typescript (or similar) when the API surface hits ~6 endpoints or when nested response shapes start showing up. The seam is the same either way.
3. The URL-composition seam from Post 4 paid off the moment the frontend showed up. Storing relative keys in the DB and composing absolute URLs at API response time is invisible discipline while no one’s looking, but it’s what makes the frontend possible without a migration when storage swaps from local to R2. The route handler doesn’t even know which storage is on the other side of url_for(). That’s the whole point of an abstraction earning its keep.
4. StPageFlip is a vanilla-JS library held inside a React component via wrapper + inner div + cleanup. The instance lives in a useRef, not in state, because flipping a page should not re-render React. A wrapper <div> belongs to React; an inner <div> belongs to StPageFlip; flip.destroy() in the effect cleanup keeps the two ownership models from stepping on each other. This pattern (an imperative third-party library wrapped in a declarative component) generalizes to most “DOM library + React” cases: Mapbox, Three.js, CodeMirror, anything that wants to own a DOM subtree. It’s worth being fluent at; it shows up everywhere.
5. Plain fetch + useState is enough for two endpoints. Three signals to graduate to TanStack Query / SWR / react-query: (a) the same data is being refetched in multiple components, (b) loading states flicker on quick re-mounts, (c) you find yourself writing your own cache. None of those bite at one screen. Adding a library before the pain hits is just speculative complexity; deferring it until the third signal lights up is when you get the most signal from the upgrade.
6. Single-page versus two-page spread is one library event plus a media-query. flip.on('changeOrientation', ...) fires whenever the viewport flips between portrait and landscape; the component forwards the new mode through a callback; the parent reshapes the page-indicator pill. Real comics have facing spreads — Pepper & Carrot episode 6 has at least one cross-gutter watercolor — and that’s an artist decision the reader UI should honor, which the spread mode does for free. Single-page mode is the safety net for narrow viewports, not the canonical view.
Appendix: Going Deeper
Three pieces of the code the main flow walked past with one-line bullets are worth a deeper look — two SQLAlchemy idioms (one per route handler) and the pydantic-settings machinery that loads .env. Each subsection below builds the concept from first principles, then circles back to the exact line in the workshop starter so the connection is visible.
The list_episodes Query, Built Up Step by Step
The list_episodes handler builds one SQL statement that returns every episode along with how many pages each one has, sorted by episode number. The interesting part is how it computes the page count efficiently — using a subquery, an outer join, and COALESCE together. This appendix builds the query up the way the code does, then explains why it’s shaped that way instead of a naive single-join.
The handler’s query, in full, for reference:
1
2
3
4
5
6
7
8
9
10
11
page_counts = (
select(Page.episode_id, func.count(Page.id).label("page_count"))
.group_by(Page.episode_id)
.subquery()
)
stmt = (
select(Episode, func.coalesce(page_counts.c.page_count, 0).label("page_count"))
.outerjoin(page_counts, Episode.id == page_counts.c.episode_id)
.order_by(Episode.episode_number.asc())
)
rows = (await db.execute(stmt)).all()
Stage 1: the subquery (counting pages per episode)
1
2
3
4
5
page_counts = (
select(Page.episode_id, func.count(Page.id).label("page_count"))
.group_by(Page.episode_id)
.subquery()
)
This piece, by itself, is asking the pages table: “for each episode, how many pages do you have?” In raw SQL:
1
2
3
SELECT episode_id, COUNT(id) AS page_count
FROM pages
GROUP BY episode_id;
Walking through the SQLAlchemy pieces:
select(Page.episode_id, func.count(Page.id))— select two columns: the episode each page belongs to, and a count.func.count(Page.id)—funcis SQLAlchemy’s gateway to SQL functions.func.count(...)generates a SQLCOUNT(...)call. We countPage.id(which is never null) rather than*— same result here, but explicit..label("page_count")— gives theCOUNTexpression a column alias, so we can refer to it later aspage_countinstead of an auto-generated name likecount_1..group_by(Page.episode_id)— collapses rows that share the sameepisode_idinto one row, so theCOUNTbecomes per-episode rather than across the whole table..subquery()— wraps the whole thing so it can be used as a virtual table inside another query, not executed on its own.
The result, conceptually, is a temporary table that looks like:
| episode_id | page_count |
|---|---|
| uuid-A | 12 |
| uuid-B | 8 |
| uuid-C | 15 |
Note one thing: episodes with zero pages don’t appear here at all. If no Page row references an episode, that episode_id never enters the GROUP BY. This matters in a moment.
Stage 2: the main query (joining episodes against the counts)
1
2
3
4
5
stmt = (
select(Episode, func.coalesce(page_counts.c.page_count, 0).label("page_count"))
.outerjoin(page_counts, Episode.id == page_counts.c.episode_id)
.order_by(Episode.episode_number.asc())
)
In raw SQL, roughly:
1
2
3
4
5
6
7
8
SELECT episodes.*, COALESCE(pc.page_count, 0) AS page_count
FROM episodes
LEFT OUTER JOIN (
SELECT episode_id, COUNT(id) AS page_count
FROM pages
GROUP BY episode_id
) AS pc ON episodes.id = pc.episode_id
ORDER BY episodes.episode_number ASC;
Three things are happening here.
The outerjoin
1
.outerjoin(page_counts, Episode.id == page_counts.c.episode_id)
This is a LEFT OUTER JOIN between episodes and the page_counts subquery. The join condition is Episode.id == page_counts.c.episode_id — match each episode to its row in the count table.
The difference between inner join and outer join matters here:
- Inner join → only return episodes that have a matching row in
page_counts. Episodes with zero pages would vanish. - Outer join (left) → return every episode, even if there’s no matching row in
page_counts. Episodes with no pages still appear, just withNULLforpage_count.
The picker UI wants to show all episodes — including any that were just created but haven’t been ingested yet, so they have no Page rows pointing at them. Outer join is the right call.
The .c in page_counts.c.episode_id means “columns of this subquery.” When you turn a select into a subquery, you access its columns through .c.<name>.
The coalesce
1
func.coalesce(page_counts.c.page_count, 0).label("page_count")
COALESCE in SQL returns the first non-NULL value from its arguments. So COALESCE(page_count, 0) means “use page_count if it has a value, otherwise use 0.”
Why this is needed: the outer join leaves page_count as NULL for any episode with no matching row in the subquery (i.e., zero pages). Without coalesce, you’d get None in Python, and the downstream code int(page_count) would crash with TypeError: int() argument must be a string... not 'NoneType'.
coalesce substitutes 0, which is the truthful answer for “episode has no pages” and a clean integer for the cast.
The pair works together: outer join keeps every episode in the result, coalesce converts the resulting NULLs to zeros.
The order_by
1
.order_by(Episode.episode_number.asc())
Sort the final result by episode_number ascending. Episode 1 first, then 2, then 3. Without this, the database can return rows in any order it likes — usually whatever’s convenient for the storage engine. For a UI that displays episodes in narrative order, you need an explicit sort.
Stage 3: executing and unpacking
1
rows = (await db.execute(stmt)).all()
.all() returns a list of Row objects — one per episode. Each row has two pieces (because the select had two arguments): the Episode ORM object and the page_count integer.
1
2
for episode, page_count in rows:
...
The tuple unpacking works because each Row behaves like a tuple. episode gets the full Episode ORM object (all its columns mapped to attributes), page_count gets the integer count.
Why a subquery instead of just joining pages directly?
This is the subtle bit. A natural-looking alternative would be:
1
2
3
4
5
6
7
# Don't do this
stmt = (
select(Episode, func.count(Page.id))
.outerjoin(Page, Episode.id == Page.episode_id)
.group_by(Episode.id)
.order_by(Episode.episode_number.asc())
)
This seems simpler — one query, no subquery. And it would work. But it has two real drawbacks:
- Grouping is awkward. When you
GROUP BY Episode.id, strict SQL dialects (like Postgres) require every non-aggregated column to appear in theGROUP BYclause too. So you’d need.group_by(Episode.id, Episode.title, Episode.slug, ...)— tedious and fragile every time you add a column toepisodes. - It mixes concerns. The
pagestable is joined directly into a query about episodes, which means the query planner has to figure out how to deduplicate. With many pages per episode, the intermediate result set is large before theGROUP BYcollapses it.
The subquery approach computes the per-episode counts first (small result: one row per episode), then joins that compact summary to the episodes table. Cleaner SQL, cleaner planner work, and the main select(Episode, ...) doesn’t need a GROUP BY at all because the join is one-to-one: each episode matches at most one row in page_counts.
The whole picture, in one mental snapshot
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
┌─────────────────────────┐
│ pages │
│ (many rows per episode) │
└───────────┬─────────────┘
│ GROUP BY episode_id, COUNT(id)
▼
┌─────────────────────────┐
│ page_counts (subquery) │
│ episode_id | page_count │
│ (one row per episode │
│ that has pages) │
└───────────┬─────────────┘
│ LEFT OUTER JOIN
│ on episodes.id = page_counts.episode_id
▼
┌─────────────────────────┐
│ episodes ⨝ page_counts │
│ + COALESCE(NULL → 0) │
│ + ORDER BY episode_num │
└───────────┬─────────────┘
▼
rows: [(Episode, count), ...]
One round trip to the database, all episodes returned with their page counts, zero counts handled correctly, results sorted.
The one-sentence version
Build a small episode_id → page count table with a GROUP BY subquery, left-join it onto episodes so every episode appears (even with zero pages), use COALESCE to turn the NULLs from that join into zeros, and order the result by episode number — all in one query.
The get_episode Query — selectinload and scalar_one_or_none()
The get_episode handler walked past two SQLAlchemy idioms with one-line explanations in the main flow:
selectinload(Episode.pages).selectinload(Page.characters)— eager loading, chained two levels deep.(await db.execute(stmt)).scalar_one_or_none()— extracting a single ORM object from the result.
Both deserve more depth than a single bullet, because both are the right answer to questions that come up in every async-SQLAlchemy app. This appendix walks each one from first principles, then circles back to the exact line in get_episode so the connection is visible.
The N+1 problem (and why selectinload is the antidote)
Suppose you fetch an episode and want to list its pages, with no eager-loading hint:
1
2
3
4
result = await db.execute(select(Episode).where(Episode.slug == slug))
episode = result.scalar_one_or_none()
for page in episode.pages: # ← what happens here?
print(page.page_number)
By default, SQLAlchemy is lazy: when you wrote select(Episode), it ran one query for the episode. The pages relationship was not loaded. The moment your code touches episode.pages, SQLAlchemy thinks “oh, you want pages now” and fires another query: SELECT * FROM pages WHERE episode_id = ?.
That’s 2 queries for one episode. Annoying, but manageable. Now add characters:
1
2
3
for page in episode.pages: # 1 extra query to load pages
for char in page.characters: # ← 1 extra query PER PAGE for characters
print(char.name)
If the episode has 10 pages, that’s:
- 1 query for the episode
- 1 query for all the pages
- 10 queries — one per page — for the characters
12 queries for one API request. Scale to 50 pages → 52 queries. This is the N+1 problem: 1 initial query, then N extra queries, one per parent row.
In async mode it’s even worse: SQLAlchemy’s default lazy loading actually raises an error in an async session, because the implicit query would block the event loop. So you’d see a crash, not just slowness — the MissingGreenlet traceback a beginner hits the first time they reach for episode.pages inside an async handler without thinking about eager loading.
selectinload tells SQLAlchemy: “when you load these episodes, also load their pages — in a separate but bulk query.”
1
stmt = select(Episode).options(selectinload(Episode.pages))
SQLAlchemy now runs:
1
2
3
4
5
-- Query 1: get the episode
SELECT * FROM episodes WHERE slug = 'ep01-potion-of-flight';
-- Query 2: get ALL pages for those episodes in one shot
SELECT * FROM pages WHERE episode_id IN (<episode_id>);
Two queries total, no matter how many pages. The pages are pre-loaded and attached to episode.pages before your code ever touches them. No more lazy loading, no surprises. The name is literal: it loads related objects using a SELECT … IN (…) query.
Chaining for nested relationships
Our handler has two levels of relationships: Episode → Pages → Characters. Pre-loading just pages isn’t enough — characters would still N+1. So we chain:
1
.options(selectinload(Episode.pages).selectinload(Page.characters))
Read this left-to-right: “when loading episodes, eagerly load pages; and when loading those pages, eagerly load characters.”
SQLAlchemy now runs three queries total:
1
2
3
4
5
6
7
8
9
10
-- Query 1: the episode
SELECT * FROM episodes WHERE slug = 'ep01-potion-of-flight';
-- Query 2: all pages for the episode
SELECT * FROM pages WHERE episode_id IN (?);
-- Query 3: all characters across all those pages
SELECT * FROM characters
JOIN page_characters ON ...
WHERE page_characters.page_id IN (?, ?, ?, …);
Three queries instead of fifty-something. By the time your handler reaches for page in episode.pages: for char in page.characters: …, everything is already in memory. No more queries fire.
Why not just JOIN everything?
There’s a sibling strategy called joinedload that does use a SQL JOIN:
1
.options(joinedload(Episode.pages))
This pulls episode + pages in one query with a JOIN. Sounds better, right? Fewer queries. But JOINs have a problem for collections: if an episode has 10 pages, the JOIN duplicates the episode row 10 times in the result set. With a second JOIN to characters, you get a cartesian explosion — 10 pages × 5 characters each = 50 rows where many fields repeat. SQLAlchemy deduplicates in Python, but you’ve still paid to transfer the redundant bytes over the wire.
selectinload avoids this. Each table is queried separately and cleanly, with no row multiplication. For one-to-many and many-to-many relationships (like Episode → Pages and Page ↔ Characters), it’s usually the right default.
The rule of thumb:
| Strategy | Best for | What it does |
|---|---|---|
joinedload | *-to-one relationships (e.g., Page → Episode, where each page has exactly one episode) | One JOIN, no row duplication. |
selectinload | *-to-many relationships (e.g., Episode → Pages) | One extra SELECT … IN (…) per relationship level. Avoids cartesian blow-up. |
Our handler uses selectinload for both hops because both are to-many: an episode has many pages, a page has many characters. (Reference: SQLAlchemy loader-strategy docs.)
What scalar_one_or_none() actually does
The other piece of the handler:
1
episode = (await db.execute(stmt)).scalar_one_or_none()
This method does three things at once: pick the first column, expect at most one row, return None if there isn’t one. Let’s unpack each.
execute() returns a Result, not the data. When you run await db.execute(stmt), you don’t get rows directly — you get a Result object. Think of it as a cursor or iterator over the rows the database sent back. You then call a method on it to extract what you actually want:
1
2
result = await db.execute(stmt) # a Result object, not data
episode = result.scalar_one_or_none() # now you have the episode (or None)
Our code just chains these together: (await db.execute(stmt)).scalar_one_or_none(). Same thing, inline.
Decoding the name piece by piece. The method name reads like three modifiers stacked together:
scalar— return just the first column of each row, not the whole row tuple. When you writeselect(Episode), the result rows are technically tuples like(Episode,)— a one-element tuple containing the ORM object.scalarunwraps that tuple and gives you just theEpisodedirectly. Without it you’d have to writerow[0]everywhere.one— expect exactly one row. If there are zero or many, raise an error.or_none— modify “one” to allow zero. So now: expect zero or one row. Multiple rows still raise.
Combine them and you get: “give me the first column of the single row, or None if there’s no row, but blow up if there are multiple rows.”
The whole Result method family
SQLAlchemy has a matrix of these methods. The pattern is easier to remember once you see them together:
| Method | Returns | Zero rows | One row | Many rows |
|---|---|---|---|---|
.scalar_one() | the value | raises NoResultFound | returns it | raises MultipleResultsFound |
.scalar_one_or_none() | the value or None | returns None | returns it | raises MultipleResultsFound |
.scalar() | the value or None | returns None | returns it | returns the first (silently ignores the rest) |
.scalars().all() | list of values | [] | [value] | [v1, v2, …] |
.scalars().first() | the value or None | None | returns it | returns the first (silently ignores the rest) |
.one() | a Row tuple | raises | returns it | raises |
.all() | list of Row tuples | [] | one-element list | full list |
Three distinctions worth flagging because they’re the ones that catch beginners:
scalar_one_or_nonevsscalar— both returnNonefor zero rows, butscalar_one_or_noneraises on multiple rows whilescalarsilently picks the first. The_oneversion is safer because it catches bugs (aWHERE slug = ?lookup should never return two rows; if it does, you want to know).scalar_one_or_nonevsscalar_one— the_or_nonesuffix turns “must exist” into “may not exist.” Use_or_nonewhen missing is a valid outcome (lookup by slug → 404 is fine). Usescalar_onewhen missing means something is broken (loading a record you just created and know exists).scalar_one_or_nonevsscalars().first()— both return one item orNone, butfirst()silently truncates if there are many.scalar_one_or_noneraises. Same safety story.
Why it’s the right choice in get_episode
1
2
3
4
5
6
7
8
stmt = (
select(Episode)
.where(Episode.slug == slug)
.options(selectinload(Episode.pages).selectinload(Page.characters))
)
episode = (await db.execute(stmt)).scalar_one_or_none()
if episode is None:
raise HTTPException(status_code=404, detail=f"Episode '{slug}' not found")
The logic decomposes neatly:
- A slug lookup should return at most one episode. The
episodes.slugcolumn has a unique constraint (seedocs/data-model.md), so two matches would be a data-integrity violation.scalar_one_or_noneraisesMultipleResultsFoundif that ever happens — loud failure, easy to debug. - Zero matches is normal. The user might request a slug that doesn’t exist. That’s a
404, not a500._or_nonereturnsNoneinstead of raising, and the next line handles it with a cleanHTTPException. - You want the ORM object, not a tuple. The
scalarprefix unwraps(Episode,)to justEpisode, soepisode.pagesworks directly withoutrow[0].pages.
All three concerns are addressed by that one method call. It’s the precise tool for “look up a single record by a unique key.”
Mental model
Lazy loading is like ordering food one bite at a time: ask for the salad, eat it, ask for the soup, eat it, ask for the main course. Many trips to the kitchen.
selectinload is telling the waiter at the start: “I want the full meal — bring it all out together.” A couple of trips to the kitchen at the start, then you eat at your own pace without interruption.
For a web request that knows what data it needs, the second pattern is almost always what you want.
And for scalar_one_or_none and its siblings, the mental model is just say what you expect, and SQLAlchemy will enforce it:
| You expect… | Use |
|---|---|
| Exactly one row, must exist | scalar_one() |
| Zero or one row, missing is OK | scalar_one_or_none() ← what get_episode does |
| A list of rows | scalars().all() |
Pick the method that matches your real expectation about the data, and SQLAlchemy will enforce it for you. Code that says what it means is code that fails loudly when the world doesn’t match, and that’s exactly the kind of failure you want.
How Settings Reads Your .env
If you’ve been wondering how settings.cors_origins in backend/app/main.py ends up containing ["http://localhost:5173"] without anyone explicitly opening a file or parsing anything, this appendix walks the chain. It’s optional reading — every other post in the series uses Settings without needing this depth — but if you’re new to pydantic-settings the magic can feel like, well, magic. The same questions resurface when an env-var change doesn’t seem to take effect, or when you want to know exactly what overrides what.
The class definition
Here’s the relevant excerpt from backend/app/config.py:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
from pathlib import Path
from pydantic import Field
from pydantic_settings import BaseSettings, SettingsConfigDict
# Anchor the .env lookup to the repo root so settings load identically
# whether the process starts from the repo root, backend/, ingestion/, or
# anywhere else. config.py lives at backend/app/config.py — parents[2] is
# the repo root.
_PROJECT_ROOT = Path(__file__).resolve().parents[2]
class Settings(BaseSettings):
model_config = SettingsConfigDict(
env_file=_PROJECT_ROOT / ".env",
env_file_encoding="utf-8",
case_sensitive=False,
extra="ignore",
)
# === Database ===
postgres_user: str = "peppercarrot"
postgres_host: str = "localhost"
# ... 30+ more fields, every one with a default ...
cors_origins: list[str] = Field(default_factory=lambda: ["http://localhost:5173"])
Three things to notice before we get to the four SettingsConfigDict arguments:
BaseSettingsis from pydantic-settings, not from pydantic itself. Pydantic-settings is a separate package layered on top of pydantic for the specific job of “load typed config from environment variables and.envfiles.” The split exists because most pydantic models don’t need that machinery — only application config does.model_configis a magic attribute name. Pydantic v2’s metaclass reads any class attribute namedmodel_configat class-definition time to configure model behavior. You never reference it from application code. It’s pydantic v2’s replacement for the olderclass Config:inner class you might have seen in v1 tutorials — same idea, cleaner syntax.- Every field has a default. That means
Settings()works even with no.envfile at all — it falls back to the in-code defaults. The.envfile is an override, not a requirement. This is what lets a brand-new contributorgit clonethe repo and runpytestwithout touching anything.
The four SettingsConfigDict arguments, one by one
Each argument configures one piece of load behavior. Removing any one of them breaks a specific thing — the table below pairs each with the concrete symptom of its absence.
| Argument | What it does | What breaks if removed |
|---|---|---|
env_file=_PROJECT_ROOT / ".env" | Tells pydantic-settings to read this specific file at construction time. | No .env is loaded at all; every field falls back to its hardcoded default. POSTGRES_HOST=postgres in .env is silently ignored. |
env_file_encoding="utf-8" | Pins the file encoding. | Reads with the system locale — usually fine on macOS/Linux, sometimes Windows-1252 on Windows. Non-ASCII values in .env (an accented password) parse differently across developers’ machines. |
case_sensitive=False | Matches env var names case-insensitively. | .env containing POSTGRES_USER=alice (uppercase, Unix convention) no longer maps to postgres_user: str (lowercase, Python convention). You’d have to write .env in lowercase, which looks wrong in a shell context. |
extra="ignore" | Drops keys in .env that aren’t fields on Settings. | Settings() raises ValidationError because .env carries VITE_API_BASE_URL=... for Vite, and pydantic doesn’t know that’s a frontend variable. The backend won’t boot. |
You can prove any of these by temporarily flipping the argument and watching what changes. For example, with case_sensitive=True:
1
2
3
4
5
6
7
cd backend && uv run python -c "
from app.config import get_settings
s = get_settings()
print('postgres_host =', s.postgres_host)
"
# Output: postgres_host = localhost
# (the DEFAULT — .env's POSTGRES_HOST=postgres no longer matches.)
Flip back to case_sensitive=False and the value becomes postgres again.
Why the _PROJECT_ROOT anchoring matters
This is subtle but important. _PROJECT_ROOT = Path(__file__).resolve().parents[2] computes the repo root from config.py’s own filesystem location — not from the current working directory. The same code is imported from multiple working directories:
cd backend && uv run uvicorn app.main:app(CWD =backend/)cd ingestion && uv run python ingest.py(CWD =ingestion/)pytestfrom the repo root (CWD = repo root)
Without anchoring — i.e., if env_file=".env" were passed as a plain relative path — pydantic-settings would resolve it against whichever CWD was active when the process launched. Three different CWDs → three different effective .env paths → “why does the backend find my .env but the ingestion script doesn’t?” three months from now. Anchoring to a __file__-derived path solves this once. Every consumer of Settings sees the same single file.
The precedence chain
When you call Settings() (or, more commonly, get_settings() which caches the result), pydantic-settings walks a fixed precedence order from highest to lowest:
- Explicit constructor arguments —
Settings(postgres_user="alice")always wins. (Used mostly in tests.) os.environ— env vars set in the shell before launch..envfile values — what’s written in the file atenv_file=….- In-code defaults — the right-hand side of each
: str = "..."declaration on the class.
Highest match wins. So if you want to override .env for one run, just prefix the command:
1
2
3
POSTGRES_HOST=other-host uv run uvicorn app.main:app
# Settings sees POSTGRES_HOST=other-host from os.environ (rank 2),
# even though .env says POSTGRES_HOST=postgres (rank 3).
The same chain governs production, but the source shifts: rank 2 (os.environ) becomes where everything comes from, because containers don’t typically ship a .env file. The next subsection unpacks that.
Where the values come from in production (Docker, Fly, Modal)
In local dev, Settings reads from your .env file at rank 3. In any containerized deployment, it usually doesn’t, and the question that always comes up the first time you deploy is “how does the container even get those env vars set?” This subsection answers that.
Two unrelated files share the name .env
Before anything else: there are two completely different .env mechanisms in the world. They share a filename and nothing else.
.env | Who reads it | When |
|---|---|---|
pydantic-settings .env (this appendix) | The Python process, inside Settings(), via env_file=…. | At runtime, on whatever filesystem Python is running on. |
Docker Compose .env | The docker compose CLI, before processing docker-compose.yml. | At orchestration time, to interpolate ${VARS} inside the compose file. |
These are unrelated. They sometimes contain different keys. People mix them up all the time. For the rest of this subsection, .env means the pydantic-settings one.
How env vars get into a container
Every Linux process inherits an environ block — a list of KEY=VALUE strings — from its parent. Docker is the parent of your container’s main process (uvicorn for us), and it sets that block based on whichever mechanism you ask for:
docker run -e KEY=VALUE— pass one variable per flag. Explicit, no file.docker run --env-file production.env— Docker reads the file on the host and converts each line to an env var on the container.docker-compose.ymlwithenvironment:— declarative form of-e. Can substitute values from Compose’s own.env(the orchestration kind) via${VAR}syntax.docker-compose.ymlwithenv_file:— declarative form of--env-file.- Platform secrets —
fly secrets set KEY=VALUEon Fly.io,modal.Secreton Modal,SecretandConfigMapresources on Kubernetes. The platform injects them into the container at boot.
All five end up in the same place: os.environ inside the container. From there, pydantic-settings finds them at rank 2 of the precedence chain.
What goes inside the image, and what doesn’t
A reasonable production Dockerfile for this project looks roughly like:
1
2
3
4
5
FROM python:3.12-slim
COPY backend/ /app/backend/
# Notice what's absent: we do NOT copy .env into the image.
WORKDIR /app/backend
CMD ["uvicorn", "app.main:app", "--host", "0.0.0.0", "--port", "8000"]
COPY .env /app/.env is intentionally missing. Baking secrets into an image is a leak: anyone who pulls the image (or scrapes the registry, or recovers a backup) can extract them. Instead:
- Your
.envfile stays on developer laptops only. - In production, your orchestrator (Compose / Fly / Modal / K8s / whatever) injects the same keys as
os.environentries on the running container. Settings()runs inside the container and:- Tries to open
env_file=/app/.env→ file doesn’t exist → that rung of the chain is silently skipped. - Reads
os.environ→ findsPOSTGRES_HOST,CORS_ORIGINS, etc. set by the orchestrator → uses those. - Anything not in
os.environfalls through to the in-code defaults.
- Tries to open
The precedence chain is unchanged; one of its rungs (the .env file) is just empty in prod.
The chain, redrawn for the two scenarios side by side:
| Rank | Source | Local dev | Production (Docker / Fly / Modal) |
|---|---|---|---|
| 1 | Settings(...) kwargs | Not used | Not used |
| 2 | os.environ | What your shell exported, if anything | Whatever your orchestrator injected ← the loaded path |
| 3 | .env file (env_file=) | Your local .env ← the loaded path | Usually absent inside the container |
| 4 | In-code defaults | Fills any gaps | Fills any gaps |
Same code, two different fill paths. That’s the property that makes a STORAGE_BACKEND=r2 change in one environment work without recompiling anything in another.
Concrete example: this project on Fly.io
When Post 15 sets up the Fly deploy (forthcoming — that post lands at the end of the series), the relevant ritual is roughly:
1
2
3
4
5
6
7
8
9
10
# One time, when first deploying:
fly secrets set \
POSTGRES_HOST="ep-quiet-…neon.tech" \
POSTGRES_USER="peppercarrot" \
POSTGRES_PASSWORD="…" \
STORAGE_BACKEND="r2" \
R2_BUCKET="peppercarrot-images" \
R2_ACCESS_KEY_ID="…" \
R2_SECRET_ACCESS_KEY="…" \
CORS_ORIGINS='["https://flipbook.pages.dev"]'
Fly stores those encrypted, and on every container boot it injects them as env vars into the process environment. Inside the container, when uvicorn starts up:
app.main:appimports →app.configruns →get_settings()constructsSettings().- pydantic-settings sees no
/app/.envfile → rank 3 skipped. - Reads
os.environ→ findsSTORAGE_BACKEND=r2,CORS_ORIGINS=[…], all the Neon and R2 credentials → uses them. get_storage(settings)seesstorage_backend == 'r2'→ returns anR2Storageinstance.- The same code that talked to
LocalStoragein dev now talks to Cloudflare R2 in prod.
No code in the workshop changes between dev and prod. Only the origin of the values does. That’s the property the Post 4 Storage Protocol was designed to land cleanly.
One non-obvious gotcha
If you mistakenly COPY .env /app/.env into the production image and your orchestrator sets the same keys via secrets, both happen, but os.environ wins (rank 2 > rank 3 in the precedence chain). So nothing visibly breaks. You’ve still leaked the dev secrets into the image, though, which is the real cost. The lesson to pin: never bake secrets into an image layer. Use the orchestrator’s secret-injection path instead.
Inspecting a loaded Settings instance
When you’re debugging “why isn’t my env var taking effect?”, the fastest tool is model_dump_json:
1
2
3
4
cd backend && uv run python -c "
from app.config import get_settings
print(get_settings().model_dump_json(indent=2))
"
That dumps every field on Settings with its currently-loaded value, regardless of whether the value came from .env, an env var, or the in-code default. If the value you see isn’t what you expect, the env var didn’t make it through one of the four layers above, and looking at the precedence chain usually tells you which.
Where this shows up in the workshop
get_settings() is called in three places in the workshop starter:
backend/app/main.py— at app startup, to readcors_origins,local_image_dir,storage_backend, etc.backend/app/api/episodes.py— via theget_storage_clientFastAPI dependency, which callsget_settings()and hands the result toget_storage(settings)to build the rightStorageimplementation.backend/app/db/session.py(indirectly) —main.pyreadssettings.database_urland passes it toinit_engine.
In every case the consumer treats Settings as a plain typed object. None of them know or care where the values came from. That decoupling is what makes “swap local for cloud” a config change: STORAGE_BACKEND=r2 in .env (plus the R2 credentials) is the only edit needed to point the same code at Cloudflare R2 instead of LocalStorage. The factory in backend/app/clients/__init__.py reads the new storage_backend value through Settings and returns a different implementation; no caller has to change.
Next up: Post 9 — The RAG Layer: Spoiler-Safe Retrieval. With a working reader telling the parent component which page the user is on (the onPageChange callback we wired up but didn’t consume yet), we can build the chat pipeline that actually grounds answers in only the pages the reader has reached. We’ll write a RetrievalService that filters Chroma queries by (episode_number, page_number) at the data layer, exercise it with curl, and prove the spoiler filter holds even when the user explicitly tries to jailbreak it. No chat panel UI yet; the streaming React panel lands in Post 10.
The workshop starter that backs this post is at https://github.com/bearbearyu1223/pepper-carrot-companion-workshop, tagged post-07-08-fullstack (shared with the Post 7 REST-API post) — pull the latest to pick up the Vite frontend and the <Flipbook> component. The full source repository and the public live-demo URL go up alongside the final post — the deploy guide — once it’s published.
Pepper & Carrot is © David Revoy, licensed CC BY 4.0. All credit to him for the source material that made this project possible.
All opinions expressed are my own.